Tutorial · Python · Twitter API · CSV
Cómo obtener y almacenar en un documento CSV tweets sobre una temática
Este tutorial legacy explica como se recopilaban tweets sobre una tematica concreta y se almacenaban automaticamente en un fichero .csv para su posterior analisis.
Vídeo explicativo
Si necesitas ayuda, puedes seguir el proceso completo en el siguiente vídeo explicativo.
1. Objetivo
Nota actual sobre la API
El ejercicio original usa Tweepy y patrones de la API de Twitter que pueden diferir de la API actual de X y de los ejemplos modernos de Tweepy. Conserva el flujo como material didactico sobre CSV, credenciales y calidad de datos, pero revisa tu nivel de acceso actual antes de intentar recolectar tweets en vivo.
En 2026, empieza cualquier proyecto nuevo revisando primero la documentacion oficial de X Developer Platform. X presenta ahora el acceso a su API como un producto moderno con facturacion basada en uso, y Tweepy documenta dos interfaces distintas: API para endpoints legacy de Twitter API v1.1 y Client/StreamingClient para Twitter/X API v2. En trabajos de investigacion, deja escrito el endpoint usado, limites de precio o cuota, ventana de busqueda, restricciones de terminos/consenso y por que la muestra es representativa.
En este proyecto vamos a generar una pequeña investigación desde el punto de vista del Big Data y de las redes sociales. Exactamente, hemos utilizado Twitter como fuente textual, una red social en la que se pueden recolectar datos de forma más sencilla y, sobre todo, inmediata.
Esto permite establecer correlaciones temporales entre la evolución del virus y la opinión de la sociedad sobre el mismo.
Esta plataforma permite el envío de mensajes en texto plano de corta longitud, con un máximo de 280 caracteres. Estos mensajes, llamados tweets, pueden capturarse mediante la API proporcionada por la propia red social.
En este ejemplo se implementará un script en Python que almacene continuamente todos los tweets publicados en español sobre el Coronavirus.
2. Contexto
La temática elegida del proyecto ha sido la enfermedad Coronavirus o COVID-19 . Este fenómeno ha tenido un enorme impacto social, sanitario y económico, convirtiéndose en un tema recurrente y presente de forma continua en medios y redes sociales.
Siguiendo esta premisa, el objetivo consiste en desarrollar un script en Python que almacene de manera continuada tweets en español sobre Coronavirus. Con este dataset pueden analizarse las distintas percepciones de los usuarios teniendo en cuenta la evolución del virus y sus consecuencias.
Además, dado que vivimos en una sociedad muy digitalizada, donde las redes sociales se han convertido en un espacio habitual de opinión pública, resulta especialmente interesante estudiar este tipo de datos.
Preguntas que se pueden investigar
- ¿Cómo ha evolucionado el virus en España por comunidades autónomas y en total?
- ¿Cómo ha evolucionado el virus a nivel mundial?
- ¿Qué repercusión han tenido en la opinión social los cambios positivos o negativos del virus?
- ¿Cómo se sienten las personas respecto al progreso del virus a nivel autonómico y mundial?
3. Implementación
El programa utilizado se puede consultar y descargar desde la URL https://github.com/al118345/Tweepy_Example .
3.1 Conseguir las API Keys y Tokens de tu cuenta de Twitter
Las claves necesarias para utilizar este programa son las siguientes:
- Consumer Key (API Key)
- Consumer Secret (API Secret)
- Access Token
- Access Token Secret
Para ello, tendremos que acceder al centro de desarrolladores de Twitter en: https://developer.x.com/
Pulsamos en Create new App y rellenamos los campos básicos de la aplicación:
- Name: nombre que daremos a la aplicación o proceso.
- Description: breve descripción de la finalidad.
- Website: web donde se usarán las claves.
El resultado se mostrará como en las siguientes imágenes:
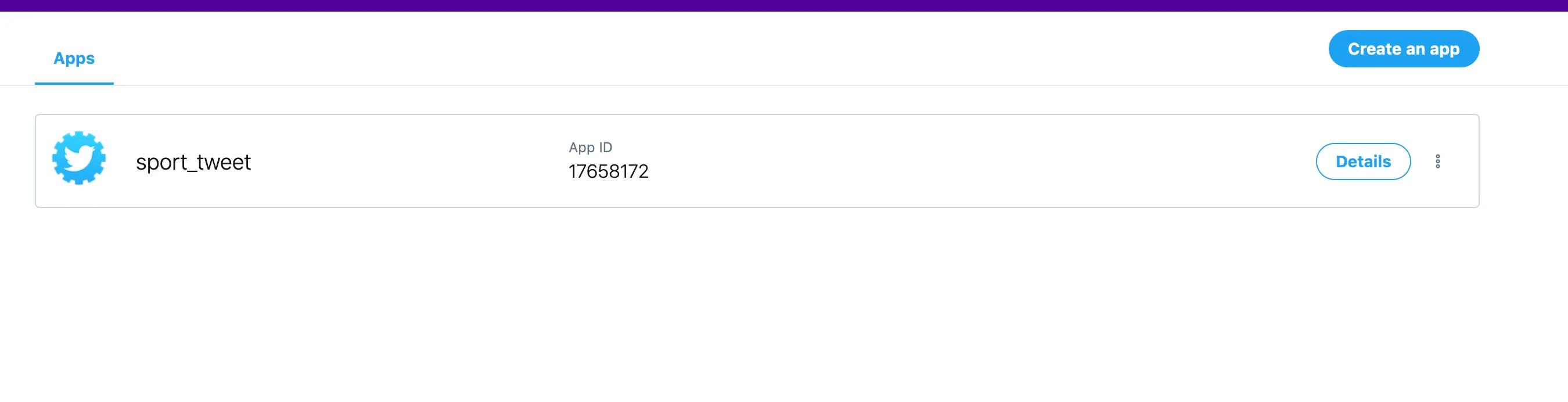
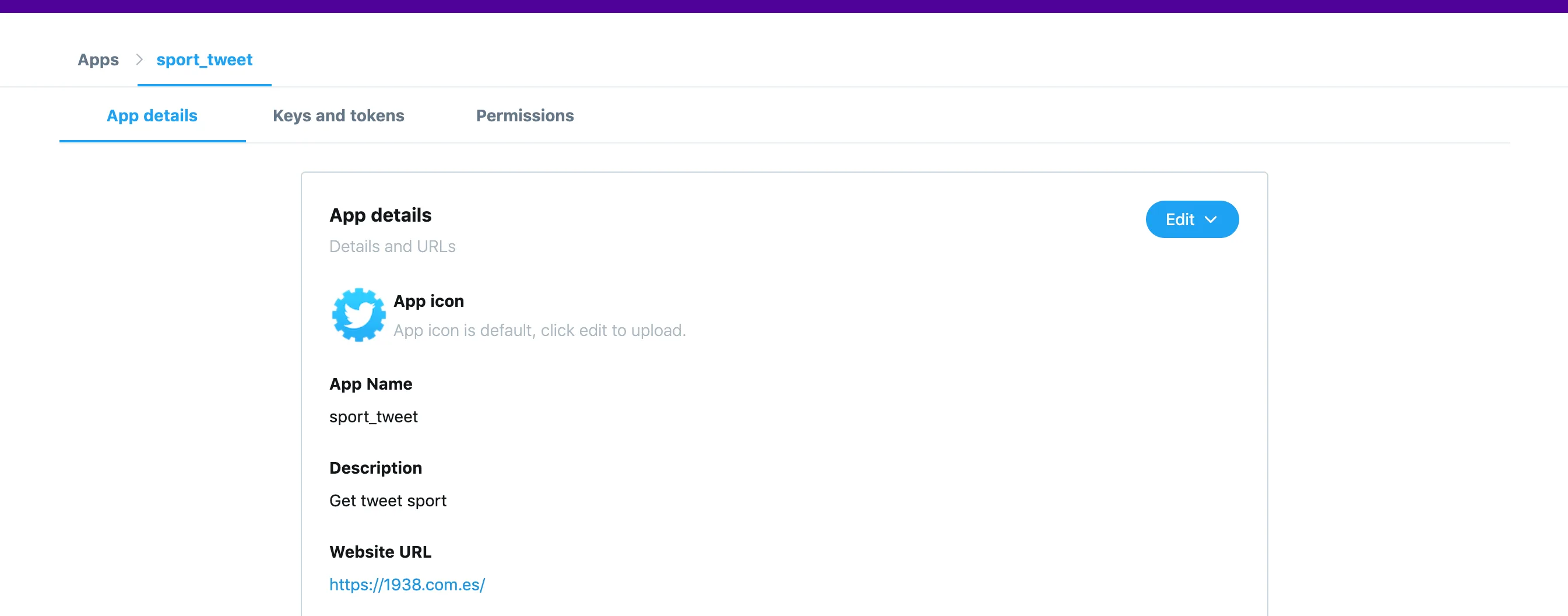
Como puede observarse, los datos pueden ser genéricos. Lo importante es completar el proceso para obtener acceso como desarrollador y conseguir la API Key.
Entrando en la pestaña Keys and Access Token podremos ver tanto la API Key como el API Secret.
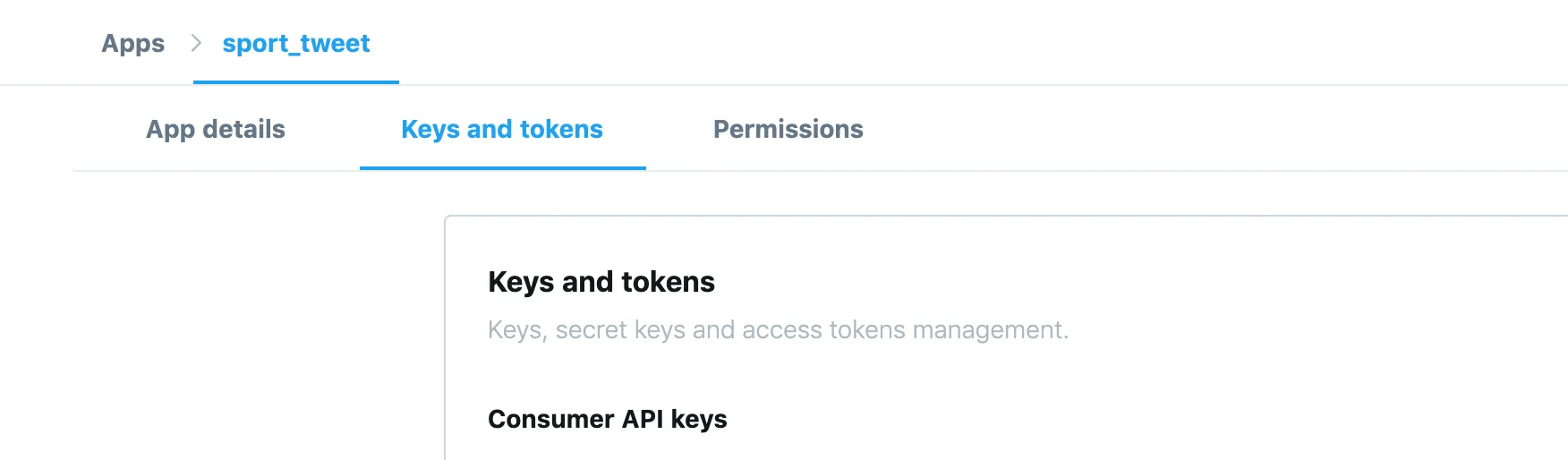
Para conseguir el token, hay que desplazarse al final de la página y pulsar el botón correspondiente. Una vez generado, ya tendremos todos los datos necesarios para conectar con Twitter.
Después, habrá que modificar el fichero autenticate_example.py:
Instalación en Windows
Instalación en Linux
3.2 Ejecutar el programa
El siguiente paso es ejecutar el programa principal situado en el fichero Tweepy_ejemplo_2022.py.
Este fichero contiene la siguiente consulta:
Como puede observarse, el programa busca todos los tweets publicados entre start_date y end_date que contengan la expresión pfizer sintomas.
El programa completo puede consultarse y descargarse desde: https://github.com/al118345/Tweepy_Example/blob/master/Tweepy_ejemplo_2022.py
3.3 Calidad del dataset y limites del analisis
Recoger tweets en un CSV es solo el primer paso. Antes de extraer conclusiones hay que revisar duplicados, retweets, spam, cambios de idioma, cuentas automatizadas y variaciones en las palabras clave. Una consulta como pfizer sintomas captura una parte concreta de la conversacion, pero deja fuera sinonimos, faltas de ortografia y mensajes que hablan del mismo tema con otras expresiones.
Tambien es importante guardar la fecha de captura, la consulta utilizada y la version del script. Si mas tarde se compara la evolucion social con datos sanitarios, esos metadatos permiten saber si una subida de mensajes responde a un hecho real, a una noticia concreta o simplemente a un cambio en la forma de recopilar datos.
Para continuar el flujo, este dataset puede conectarse con articulos de preparacion de datos, etiquetado y descubrimiento de texto y analisis descriptivo e inferencial.