Minería de estructura web: PageRank, HITS, hubs y autoridades
La minería de estructura trata la Web como un grafo. Los enlaces no son solo navegación: revelan autoridad, comunidades, recomendaciones y señales de ranking.
Grafo
Las páginas son nodos y los hiperenlaces son aristas dirigidas.
Autoridad
Las buenas páginas reciben enlaces significativos desde páginas relevantes.
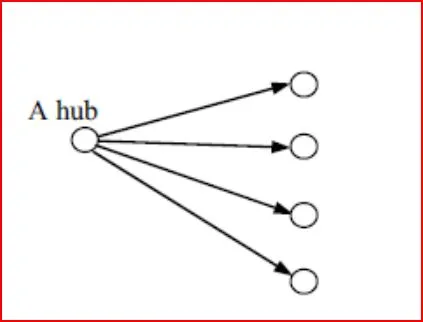
Hubs
Los hubs apuntan a varias autoridades útiles dentro de un tema.
Algoritmos
PageRank, HITS y cocitación convierten enlaces en señales medibles.
1. Definición y objetivos de la minería de estructura de la web.
El World Wide Web es un corpus de hipertexto de gran tamaño y en continua expansión. Esto significa que está formado por un conjunto de páginas web sin ningún tipo de estructura unificada y además con variabilidad en el estilo y contenido. Este nivel de complejidad hace imposible aplicar técnicas de un gestor de base de datos y recuperadores de información a los que estábamos acostumbrados en los procesos tradicionales.Para intentar solucionarlo se han desarrollado algoritmos que explotan la estructura de hipervínculos de la WWW y así se intenta solucionar el descubrimiento de información y categorización, la construcción de listas de recursos de alta calidad y el análisis de las comunidades online enlazadas. Y es en este último aspecto donde se han desarrollado los avances más significativos. La estructura de hipervínculos implica una estructura social subyacente para crear páginas y los enlaces a otras webs de otros autores. El objetivo es desarrollar técnicas que se aprovechen de lo que observamos sobre la organización social intrínseca en la web mientras diseñamos algoritmos que minen información de los hiperenlaces.La minería de estructura de la Web se definiría entonces como el proceso de usar la teoría de grafos para analizar los nodos y la estructura de conexión de un sitio web. Es decir, representaremos las webs como Nodos de un grafo y las conexiones como vértices. Para generar este tipo de estructura tendremos que realizar el siguiente procedimiento:
Extraer patrones de los hipervínculos en la web. Un hipervínculo es un componente estructural que conecta la página web a una localización diferente.
Minar la estructura del documento. Consiste en usar la estructura en forma de árbol para analizar el XML o el HTML dentro de la página web.
Aplicar una métrica a la información obtenida.
2. Definición, modelado y uso de las nociones de:
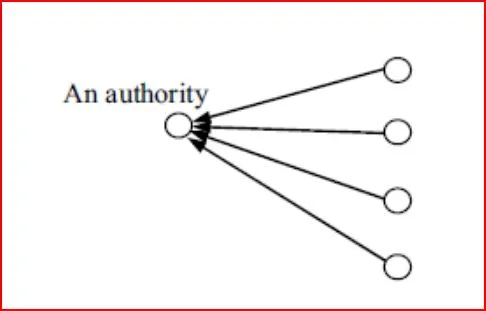
Autoridad (authoritative page), prestigio
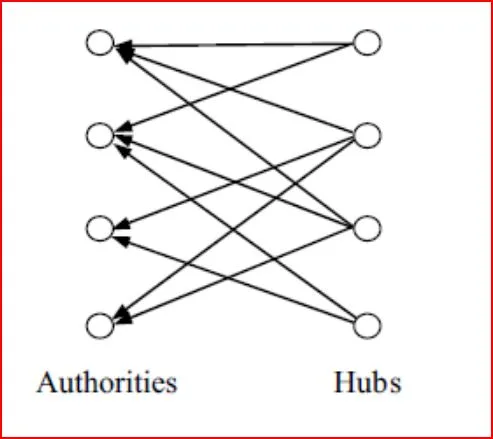
Realmente en el proceso de búsqueda no queremos localizar un conjunto de páginas relevantes sino queremos únicamente las páginas relevantes de mayor calidad. Para ello, tendremos que limitar las búsqueda hasta un tamaño sensato para un observador humano aplicando métodos que identifiquen las páginas con más “Autoridad”. Una forma de obtener esta métrica es mediante los enlaces. Como hemos analizado, la creación de un enlace por el autor de una página web representa un tipo implícito de “aprobación" a la página que se apunta. Recolectando el conjunto de tales “aprobaciones”, se puede obtener una comprensión más profunda tanto de la relevancia como de la calidad de los contenidos de la web apuntada por todo ellos. Ahora bien este sistema no es perfecto, también hay dificultad en usar la información de los hiperenlaces. Pese a que muchos enlaces representan el tipo de aprobación que se describió anteriormente, otros se crean por razones que no tienen nada que ver con el otorgamiento de autoridad. Por ejemplo algunos enlaces existen sólo para propósitos navegacionales (“Haga clic para irse arriba”) o como anuncios pagados. Otro problemas es que en las autoridades no enlazan directamente a otro ya que de esta forma evitan perder usuarios.Para solucionar estos problemas, primero tenemos que detectar cuándo una página relativamente anónima (no posee referencias) es relevante. Normalmente en estos casos siempre nos encontramos con páginas que enlazan a una colección de sitios prominentes en un tema común y, por lo tanto, serán como concentradores de autoridad (Hubs). Pueden aparecer en una variedad de formas, desde listas de recursos profesionales, hasta listas de vínculos recomendados en páginas web individuales. Los concentradores normalmente tienen pocos enlaces apuntandoles ya que otorgan autoridad sobre un tema en concreto. De esta manera, tienen un papel que es dual al de las autoridades: una buena Autoridad es aquella que es apuntada por muchos buenos concentradores. . Esta relación mutuamente reforzada entre los hubs y las autoridades servirán como tema central para la exploración de métodos basados en enlaces en la búsqueda, la compilación automatizada de recursos web de alta calidad, y el descubrimiento de comunidades web temáticamente cohesionadas.
Centralidad
En la estructura web, el nodo central es aquella estructura, sitio o documento web central que,generalmente, proporciona la mayor parte de las conexiones a otros miembros, autoridades, etc. Para analizarlo existen varios modos dependiendo de las características de la red:
Autovector de centralidad de Bonacci Se utiliza únicamente para análisis análisis de hipervínculo en redes simétricamente conectadas. Además de eso las frecuencias de las conexiones de los vínculos entre sitios web no deben ser binarias.
Grado de neutralidad de Freeman Este método de análisis es utilizado para las redes de enlaces direccionales. Mide el número de conexiones directas de un sitio web con otros. Para ello, utiliza:
Grado de neutralidad entrante
Se calcula basándose en el número de enlaces que un sitio web recibe de otros sitios. Nos sirve para calcular distancias .Nos sirve para calcular distancias .
Grado de neutralidad saliente
Se determina con el número de vínculos que se originan en un sitio.Nos sirve para calcular distancias .
Closeness
Métrica en la proximidad de dos sitios.
Betweenness
Es la métrica basada en la interposición de los sitios analizados. Por ello, esta medida se refiere a la frecuencia con con la que un sitio web se encuentra entre pares de otros sitios.
La centralidad de Negopy.
Número medio de vínculos requeridos para alcanzar a cada uno de los otros sitios web en el grupo, de tal forma que cuanto más bajo sea el valor.
Co-cita
El análisis de co-cita es usado para mapear la relación temática de conjuntos de autores, diarios o artículos. Esta relaciones normalmente se expresa en grafos donde:
Un nodo es una página web
Cada arista no dirigida posee un peso
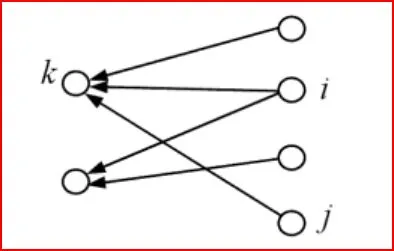
La co-citación es utilizada para medir la similitud de dos documentos. Para generar el análisis tenemos escoger el conjunto a observar, por ejemplo, los documentos k, i,j y d. Una vez escogidos nos damos cuenta que los documentos i y j están citados por el documento k. Si el documento i y el documento j están citados por otro papel, significa que i y j tienen una relación o son similares.1 Co-citaDejar L ser la matriz de citación. Cada celda de la matriz es definida como : Lij = 1 si el papel i cita al papel j, y L = 0 si es de otra manera. La Co-citación (denotada por C j es una medida similar definida como el número de papeles que co-citan i y j, y es computado con: Ci,j=∑k=0nLkiLkj donde n es el total de números de páginas. Cii es naturalmente el número de papeles que citan i. Una matriz cuadrada C puede ser formada con C ij, y es llamada matriz de citación. La co-citación es simétrica, Cij = Cji, y es comúnmente usado como medidas de similitud de dos papeles en clustering a un grupo de papeles de tópicos similares juntos.
3. Ranking de páginas web basado en enlaces:
3.1 PageRank
PageRank ha emergido como el modelo de análisis de enlace dominante para los motores de búsqueda, particularmente debido a la evaluación de consultas independientes de las páginas web, para evitar el spamming.Se basa en la naturaleza democrática de la web utilizando su estructura de enlaces como indicador de la calidad individual de cada página. PageRank interpreta hiperenlaces de una página x a una página y como un voto, de la página a; a la página y. Sin embargo, PageRank busca un número de votos legal, o enlaces que reciba una página. También analiza las páginas que emiten el voto. Los votos emitidos por las páginas que son de importante peso ayudan a las otras páginas para tener mejor puntuación. Esta es la idea del ranking de prestigio en las redes sociales.
3.2 Algoritmo de PageRank
PageRank es un ranking estático de páginas web en el sentido de que un valor de PageRank es computado por cada página off-line y no depende de las consultas de búsqueda. Para este algoritmo se puede otorgar como un valor de "prestigio" a cada página. Los principales conceptos en los contextos web son los siguientes:
In-Links de la página i: Son los hiperenlaces que apuntan a una página i de otras páginas. Usualmente, los hiperenlaces de un mismo sitio no son considerados.
Out-Links de la página i: Son los hiperenlaces que apuntan a otras páginas desde una página i. Usualmente, los hiperenlaces de un mismo sitio no son considerados.
Desde otra perspectiva, aplicando el concepto de prestigio existe la siguiente derivación del algoritmo de PageRank:
Un hiperenlace de una página apuntando a otra página es un transporte de autoridad a la página de destino. Así, los enlaces de entrada que recibe una página i, dan más prestigio de lo que la página i tenía antes de ello.
Las páginas que apuntan a una página i también tienen sus puntuaciones de prestigio en el poder. Una página con un prestigio alto que apunta a una página i es más importante que una página con poco prestigio que apunta a i. En otras palabras, una página es importante si es apuntada por otras páginas que son importantes.
Acorde con estas afirmaciones, la importancia de las páginas i, es determinado resumiendo las puntuaciones de PageRank de todas las páginas que apuntan a i. Una página que apunta a muchas otras páginas, reparte el prestigio que tiene sobre todas las páginas a las que apunta. Para formular las ideas explicadas, tratamos la Web como un grafo directo G = (V,E) donde V es un conjunto de vértices o nodos, por ejemplo, V es el conjunto de todas las páginas y E es el conjunto de enlaces directos (los hiperenlaces) . Sabiendo que el número de páginas totales en la Web es de n(n=/F/) . El PageRank de la página i(P(i)) es definido por: P(i)=∑(i,j)∈EOjP(j) donde Oj es el número de enlaces salientes de la página j. Matemáticamente, usamos un sistema de n ecuaciones lineales con n incógnitas. Este sistema lo podemos representar mediante un matriz de ecuaciones sabiendo que P es una columna de vectores n-dimensionales de valor del PageRank. Por ejemplo P=(P(1),P(2),...P(n))r Dado A como la matriz de adyacencia de nuestro grafo con: Aij={Oi10SI(i,j)∈Erestodecasos} Nosotros podemos escribir el sistema de n ecuaciones con P=ATP y definir el propio sistema. Para solucionarlo podemos aplicar un algoritmo iterativo pensando que 1 es el mayor valor y el PageRank es el vector P.Ahora bien, ¿Cumple todas las condiciones para aplicarlo a un grafo con información web?. No. Para introducir estas condiciones nos vamos en la cadena de Markov.En esta cadena, cada página web o nodo en el grafo es recordado como un estado. Un hiperenlace es una transición que lleva de un estado a otro con una probabilidad. Esto modela una navegación web aleatoria, navegando por la red como un estado de transición. Cada probabilidad de transición es Oj1 (asumiendo que el navegante cuando hace click en los hiperenlaces en la página i uniformemente de forma aleatoria). Dada una matriz de probabilidad de transición de estados A, una matriz cuadrada de la siguiente manera: A=A11A21..An1A12A22..An2....................A1nA2n..Anm Aij representa la probabilidad de transición de un usuario en el estado i al estado j.Dada un vector de distribución de probabilidad inicial Po=(Po(1),Po(2),...,Po(n))T y una matriz de probabilidad de transición A, tendremos: ∑i=0nPo(i)=1∑ji=1nAij=1 Para todas aquellas páginas web que tengan enlaces de salida. Una vez definidas las igualdades, si la matriz A que estamos analizando cumple las condiciones de la ecuación diremos que A es una matriz estocástica de la cadena de Markov. Otro detalle muy importante a tener en cuenta es que en el grafo nunca se podrán calcular nodos que no posean ningún enlace en el sistema. Si los hubieran, podremos realizar dos procedimientos:
Eliminar los nodos que impiden el cálculo. Estas páginas no afectarán el proceso de computación del Pagerank de otra página de forma directa. Los enlaces de salida de otras páginas apuntando a esas páginas también serán borrados. Después de que el PageRank se haya computado, estas páginas y los hiperenlaces que apuntan a estas, pueden ser añadidos al grafo.
Añadir un conjunto completo de enlaces de salida de cada página. Por ejemplo le añadimos a todos los nodos un enlace a las páginas X, Z y W y, de este modo, la probabilidad de transición de ir de una página i a cada página es 1/3 asumiendo una probabilidad uniforme.
3.3 PageRank como algoritmo iterativo
Para implementar este concepto, tenemos primero que tener claro dos conceptos
Un grafo directo G=(V,E) está directamente relacionado si y solo si, para cada par de nodos , hay una ruta de u a v.
Un estado i es periódico con k > 1 si k es el número más pequeño de todas las rutas que hay desde el estadio anterior a i hasta i teniendo la longitud que es k. Si el estado no es periódico, es aperiódico.
Así, el valor del PageRank de las páginas web puede ser creado usando un método de iteración, que produce el principal vector propio con el valor propio de 1. El algoritmo es simple. Comenzamos con un valor de asignación de PageRank y la iteración termina cuando el valor de PageRank deja de variar. El algoritmo sería el siguiente:
4. HITS
HITS es sinónimo de Hypertext Induced Topic Search un algoritmo de clasificación estática que depende de la consulta de búsqueda. Cuando el usuario hace una consulta, la lista de webs exitosas amplía la lista de páginas relevantes devuelta por un motor de búsqueda y, a continuación, produce dos clasificaciones según:
Rango de autoridad
Consideraremos una autoridad aquella página que reciba muchos enlaces de otras web debido a que solamente aquella aquellas que posean un buen contenido o autoridad sobre algún tema recibirán los enlaces de los otros usuarios.
Hub ranking Un hub es una página con muchos de los enlaces. La página sirve como un organizador de la información sobre un tema en particular y apunta a muchas páginas que son una buena fuente sobre el tema.
La idea clave de HITS es que un buen centro de los puntos que apunte a muchas autoridades buenas y una buena autoridad es apuntada por muchas webs que son importantes. Por lo tanto, las autoridades y los centros tienen una relación de refuerzo mutuo.
5. Análisis de comunidades en la web
Internet da cobijo a un gran número de comunidades con un interés común manifestándose como un conjunto de páginas web. A pesar de que muchas comunidades son definidas explícitamente (grupos de noticias, colecciones de recursos en portales, etc) la gran mayoría son implícitos. Identificar estas comunidades ayudaría a entender la evolución social e intelectual de la web y proporcionar información detallada a un conjunto de gente con ciertos intereses en el punto de mira. Pero claro, debido al continuo flujo evolucionarlo de internet, es difícil encontrar y analizar estas comunidades usando únicamente esfuerzo manual.Una posible solución al problema consiste en tratar la web como un enorme grafo dirigido. Se basa en que las comunidades web temáticamente cohesivas contienen en su núcleo un denso patrón de enlaces de Hubs(Concentradores) a Autoridades.Para poner esto en un lenguaje más orientado a la teoría de grafos: Se usa la noción de grafo bipartito dirigido ( Grafo cuyos nodos puedan ser divididos en dos conjuntos A y B de forma que cada enlace en el grafo se dirige del nodoA al nodo B. Dado que las comunidades que se buscan contienen grafos bipartitos dirigidos con una gran densidad de aristas, se espera que muchos de ellos contengan subgrafos más pequeños que sean de hecho completos: Cada nodo en A tiene un enlace a cada nodo en B. Usando algoritmos de "poda"(Una variante del Backtracking mejorado sustancialmente) (pruning) se pueden enumerar todos los subgrafos de la Web en un PC Standard en unos tres días de ejecución.
6 Otras aplicaciones de la minería de estructura
El objetivo principal de la minería de estructura es extraer previamente relaciones desconocidas entre las páginas Web. Esta estructura de minería de datos permite el uso de una empresa para vincular la información de su propio sitio Web para permitir la información de navegación y de grupo en los mapas de sitio. Pos su parte, los usuarios obtienen la posibilidad de acceder a la información deseada a través de la asociación de palabras clave y la minería de contenido.En la WWW, el uso de la minería de estructura permite la determinación de la estructura similar de páginas web de la agrupación a través de la identificación de la estructura subyacente. Esta información puede ser utilizada para proyectar las semejanzas de contenido web y utilizarlo para mantener o mejorar la información de un sitio para permitir el acceso de las arañas web. La minería de estructura también se puede aplicar al mundo de los negocios. Puede ser muy útil para determinar la conexión entre dos o más sitios Web de negocios y analizar en qué podemos diferenciarlos para hacerlo más atrayente. Esta información es útil para el mapeo de las empresas que compiten a través de enlaces de terceros, Su finalidad será, analizar los datos para que los usuarios acceden primero a los enlaces que interesan a la empresa y dan más beneficios- Otro aspecto de la minería de estructura en este campo es la mejora de la navegación de estas páginas a través de sus relaciones y jerarquía de enlace de los sitios Web, bastante interesante para incentivar al usuario acceder a nuestra web.Con la mejora de la navegación de páginas Web en los sitios de negocios indirectamente se mejora el motor de búsqueda, Esta conexión más fuerte permite la generación de tráfico a un sitio de negocios para proporcionar resultados que sean más productivos. Esta mejora de la navegación atrae a los robots a las ubicaciones correctas proporcionar la información solicitada, demostrando ser más beneficiosa en los clics a un sitio en particular.Como conclusión, la minería web y el uso de la minería de estructura pueden proporcionar resultados estratégicos para la comercialización de un sitio Web para la producción de la venta. El tráfico más dirigido a las páginas web de un sitio en particular aumenta el nivel de visitas regresar al sitio y recordar los motores de búsqueda sobre la información o producto proporcionado por la empresa. Esto también permite a las estrategias de marketing proporcionar resaltados que sean más productivos a través de navegación de las páginas con enlaces a la página principal del sitio en sí. Para realmente aprovechar su sitio web como una herramienta de negocio en la Web la minería de estructura se convierte en una necesidad.
7 Áreas de investigación relacionadas
Como bien hemos ido viendo a lo largo de todo este curso, la Minería de Estructura se encuentra dentro del término global de Minería de la Web. que está compuesto por tres tipos de minería:
Minería Web de Contenidos (WCM, Web Content Mining).
Clasifica los documentos automáticamente o construye una base de información web multicapa
Minería Web de Estructura (WSM. Web Structure Mining).
Extrae la estructura de una página web. WUM descubre patrones de acceso a las páginas en los usuarios
Minería Web de Uso (WUM. Web Usage Mining).
En resumen WSM extrae la estructura de los hiperenlaces, es decir, cómo están los documentos estructurados respecto a los otros (estructura interdocumental a diferencia de la estructura intra documental de WCM). La estructura se representa como un grafo de los enlaces en un sitio web o entre sitios web. WSM revela más información que la información contenida en los documentos: por ejemplo, los enlaces que apuntan a un documento pueden indicar la popularidad o importancia de un documento. mientras que los enlaces salientes indican la riqueza o variedad de los temas que contiene. Esto nos lleva a una organización jerárquica por temas que puede ser inferida directamente de los patrones de enlazado. Es posible incluso no especificar los documentos mediante palabras clave, sino mediante documentos ejemplares.
8 Conferencias internacionales
Algunas de las conferencias internacionales que abordan el tema de la minería de la web y que concretamente tratan el tema de la minería web de estructura son las siguientes:
International World Wide Web Conference(IW3C2).
Asia-Pacific Web Conference (APWeb 2008)
International Conference on Internet and Web Engineering
International Workshop on Web Mining for E-commerce and E-services (WMEE 2008) I
International Conference on Web Intelligence, Mining and Semantics
International Conference on Web-based Learning (ICWL 2010)
Web Information Systems Engineering (WISE 2008)
Call for book chapter: Web Mining Applications in E-commerce and E-services (Abril 2008)
International Conference on Web Information Systems and Mining (WISM2010)