Introducción al Aprendizaje por Refuerzo.
Guía de lectura actual
Este artículo explica el trabajo DQN de 2015 y debe leerse como fundamento, no como el estado final del aprendizaje por refuerzo profundo. Un proyecto actual distingue el final natural de un episodio del corte por límite temporal, documenta wrappers y semillas, y comunica varias ejecuciones en lugar de elegir una curva favorable.
- Usa APIs mantenidas como Gymnasium y fija versiones del entorno, las ROM y las librerías.
- Comienza con una política aleatoria y una prueba tabular o supervisada pequeña antes de entrenar.
- Separa retorno de evaluación y entrenamiento, publicando varianza, semillas y presupuesto de cómputo.
- DQN encaja con acciones discretas; el control continuo suele requerir otra familia de algoritmos.
1. Introducción
El artículo base del artículo es [Human-level control through deep reinforcement learning] [1]2. Descripción de la temática.
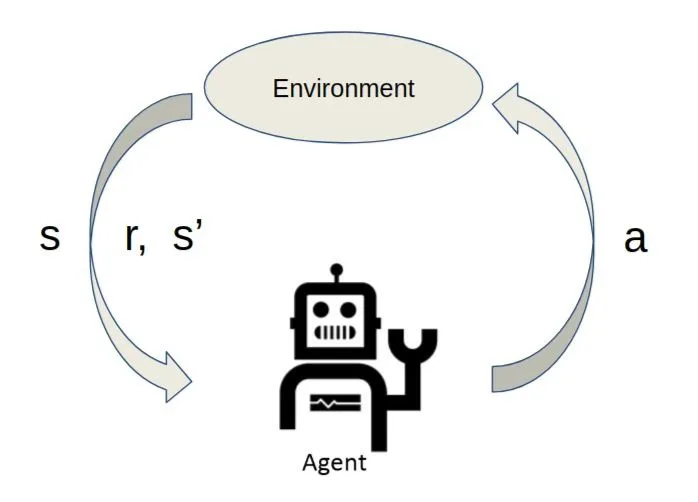
Todos los seres vivos exhiben algún tipo de comportamiento, en el sentido que realizan alguna acción como respuesta a las señales que reciben del entorno en el que viven. Algunos de ellos, además, modifican su comportamiento a lo largo del tiempo, de forma que ante señales equivalentes se comportan de forma distinta con el paso del tiempo. El aprendizaje por refuerzo es un área del machine learning inspirada en este concepto, cuya ocupación es determinar qué acciones debe escoger un agente de software en un entorno dado con el fin de maximizar alguna noción de "recompensa".3. Novedades que presenta el artículo.
Los algoritmos de aprendizaje por refuerzo han intentado simular la psicología conductista con excelentes resultados para entornos muy controlados y de baja dimensionalidad . Sin embargo, hasta la fecha de la publicación del articulo nunca se habían obtenido unos resultados tan exitosos en entornos con tanta alta dimensionalidad y tan cambiantes como los juegos clásicos de Atari 2600.En el texto utilizan los avances recientes en el entrenamiento de redes neuronales profundas para desarrollar un agente artificial, denominado red Q profunda, que puede aprender políticas exitosas directamente de entradas sensoriales de alta dimensión utilizando aprendizaje de refuerzo de extremo a extremo.4. Resumen de la parte experimental
Para analizar la parte experimental, necesitamos empezar definiendo los siguientes conceptos:- Política (policy): termino utilizado para referirse a las acciones qué decidirá el agente. La política -voraz consiste en que el agente casi siempre tomará la mejor acción posible dada la información que posee.
- Exploración vs explotación: De vez en cuando, con una probabilidad de , el agente tomará una acción completamente al azar. De esta forma, si tras la primera acción el agente ha obtenido una recompensa positiva, no se quedará atascado escogiendo esa misma acción todo el rato. Con probabilidad el agente explorará otras opciones. Este valor es parametrizable y será el encargado de equilibrar la exploración y explotación
5. Conclusiones y resumen crítico del artículo
En el articulo escogido se demuestra como, a partir de los píxeles y la puntuación del juego, el agente de la red Q profunda pudo superar el rendimiento de todos los algoritmos anteriores y alcanzar un nivel comparable al de un probador profesional de juegos humanos en un conjunto de 49 juegos, utilizando el mismo algoritmo, arquitectura de red e hiperparámetros. Este trabajo cierra la brecha entre las entradas y acciones sensoriales de alta dimensión, lo que resulta en el primer agente artificial que es capaz de aprender a sobresalir en una amplia gama de tareas desafiantes. En conjunto, este trabajo ilustra el poder de aprovechar las técnicas de aprendizaje automático de última generación con mecanismos biológicamente inspirados para crear agentes que soncapaz de aprender a dominar una gran variedad de tareas desafiantes.6. Ejemplo de código
En el repositorio https://github.com/al118345/OpenAi_Examples he dejado disponible varios ejemplos de código que intentan resolver los juego de la Atari2600. Además, he subido el video https://www.youtube.com/watch?v=Z2DbDXeNJOc que espero que os sirva de ayuda para entender la temática del video.7. Cómo continuar después de esta introducción
Una buena ruta de aprendizaje es empezar por métodos tabulares, donde los espacios de estados y acciones son lo bastante pequeños como para entender cada actualización, y pasar después al aprendizaje profundo por refuerzo cuando el número de estados hace inviable usar una tabla. Así se entiende mucho mejor la diferencia entre Q-Learning y DQN.
Lecturas relacionadas: aprendizaje por refuerzo tabular, aprendizaje profundo por refuerzo con Lunar Lander y Google Research Football.
Bibliografía
1.Titulo
Human-level control through deep reinforcement learning
Autor
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Rusu, Andrei A and Veness, Joel and Bellemare, Marc G and Graves, Alex and Riedmiller, Martin and Fidjeland, Andreas K and Ostrovski, Georg and others
Publicacion
nature
2.Titulo
Aprendizaje por refuerzo
Autor
Publicacion
Wikipedia