Python · Series temporales · Ensembles
Series temporales y ensembles de clasificadores con Python
Este post resume el notebook original en dos bloques conectados: predicción de series temporales mediante descomposición y modelos estacionales, y combinación de clasificadores mediante bagging, boosting, stacking y cascading.
Idea principal
La práctica no compara modelos de forma aislada. Enseña a construir soluciones por composición: en series temporales se separan tendencia, estacionalidad y transformación; en clasificación se combinan varios modelos para mejorar estabilidad o capacidad predictiva.
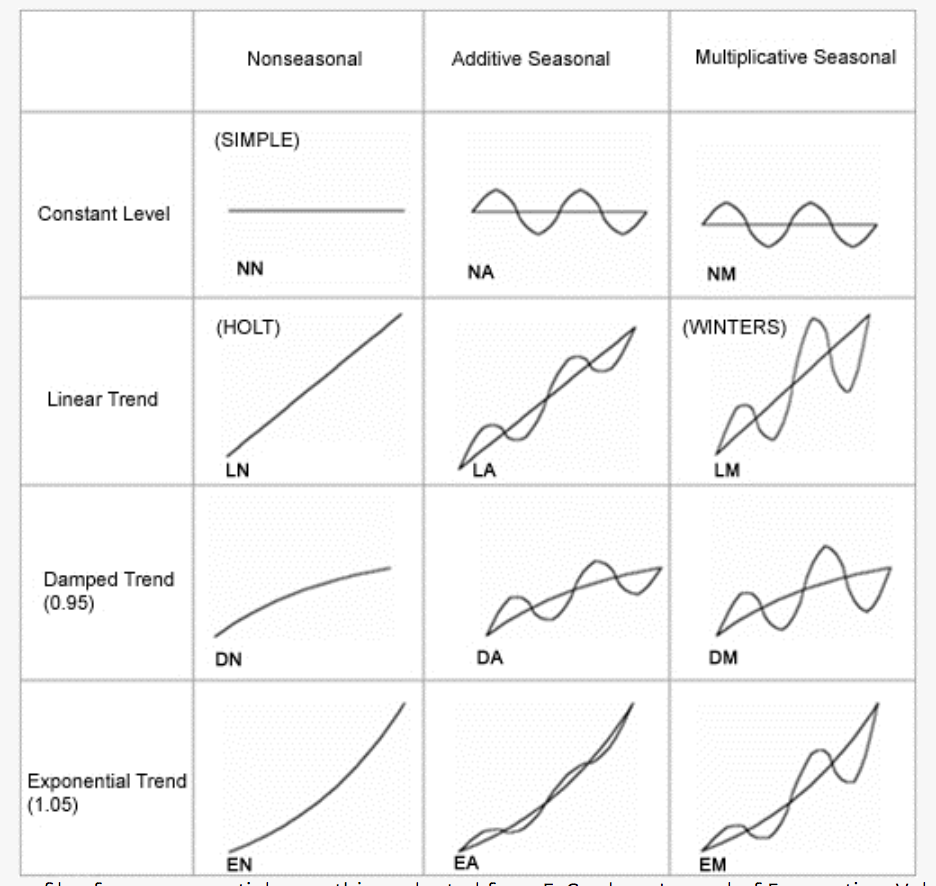
Descomposición
Separar heterocedasticidad, tendencia y estacionalidad permite interpretar qué parte explica cada patrón.
SARIMA
Modela dependencia temporal y componente estacional cuando la serie tiene un periodo claro.
Bagging y boosting
Combinan clasificadores en paralelo o secuencia para reducir varianza, sesgo o errores repetidos.
Stacking y cascading
Usan salidas de modelos base como entrada o apoyo para modelos de nivel superior.
Conclusión práctica
La mejora no viene solo de usar un algoritmo más potente, sino de estructurar bien el problema: transformar, validar, comparar y combinar modelos de forma controlada. El notebook completo queda debajo.


























{kind=link}