MuZero: planificacion con un modelo aprendido
Resumen del artículo, no receta de producción
MuZero aprende las representaciones necesarias para planificar sin reconstruir cada detalle del entorno. Es un resultado influyente, pero reproducirlo exige mucho cómputo y controlar búsqueda, replay, evaluación y versiones. Trata la implementación enlazada como educativa si no documenta commit, dependencias, semillas y recursos.
2. Novedades que presenta el artículo.
Los algoritmos de aprendizaje por refuerzo han intentado simular la psicología conductista con excelentes resultados para entornos muy controlados y de baja dimensionalidad . Los métodos de planificación basados en árboles han tenido un gran éxito en dominios desafiantes, como chess1 y Go2. Sin embargo, en los problemas del mundo real, la dinámica que gobierna el medio ambiente suele ser compleja y desconocida. En el articulo [Mastering atari, go, chess and shogi by planning with a learned model] el algoritmo MuZero combina una búsqueda basada en árboles con un modelo aprendido, logrando un rendimiento sobrehumano en una variedad de dominios desafiantes y visualmente complejos, sin ningún conocimiento de su dinámica subyacente. Este algoritmo aprende un modelo iterable que produce predicciones relevantes para planificar: la política de selección de acciones, la función de valor y la recompensa. Cuando se evaluó en 57 juegos Atari diferentes, el algoritmo MuZero logró un rendimiento de vanguardia. Cuando se evaluó en Go, ajedrez y shogi (entornos canónicos para la planificación de alto rendimiento), el algoritmo MuZero coincidió, sin ningún conocimiento de la dinámica del juego, con el rendimiento del algoritmo AlphaZero5 .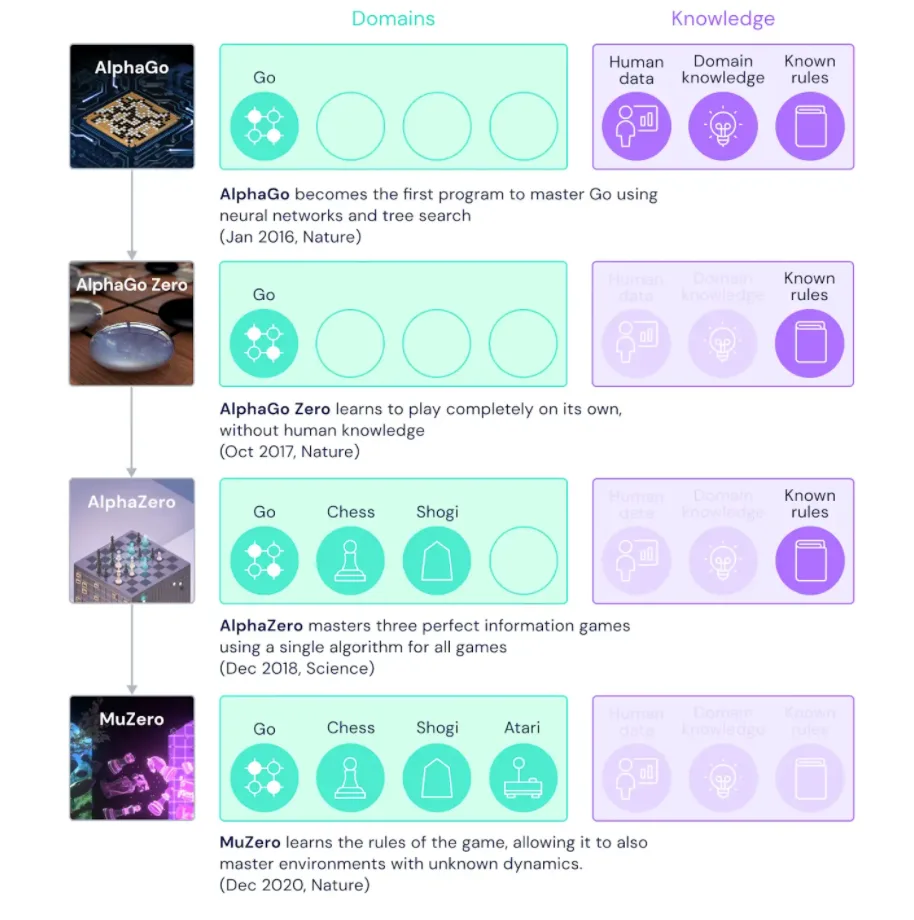
3. MuZero.
La idea principal del algoritmo es predecir aquellos aspectos del futuro que son directamente relevantes para la planificación. El modelo recibe la observación (por ejemplo, una imagen del tablero Go o la pantalla Atari) como entrada y la transforma en un estado oculto. A continuación, el estado oculto se actualiza iterativamente mediante un proceso recurrente que recibe el estado oculto anterior y una siguiente acción hipotética. En cada uno de estos pasos, el modelo produce una política (que predice el movimiento a jugar), una función de valor (que predice la recompensa acumulada, por ejemplo, el eventual ganador) y una predicción de la recompensa inmediata (por ejemplo, los puntos obtenidos al jugar un movimiento ). El modelo se entrena de punta a punta, con el único objetivo de estimar con precisión estas tres cantidades importantes, para que coincida con la política mejorada y la función de valor generada por la búsqueda, así como con la recompensa observada. No existe un requisito o restricción directa sobre el estado oculto para capturar toda la información necesaria para reconstruir la observación original, reduciendo drásticamente la cantidad de información que el modelo tiene que mantener y predecir. Tampoco hay ningún requisito para que el estado oculto coincida con el estado real y desconocido del entorno; ni ninguna otra restricción sobre la semántica del estado. En cambio, los estados ocultos son libres de representar cualquier estado que calcule correctamente la política, la función de valor y la recompensa. Intuitivamente, el agente puede inventar, internamente, cualquier dinámica que conduzca a una planificación precisa.4. Conclusiones.
MuZero ha igualado el rendimiento sobrehumano de los algoritmos de planificación de alto rendimiento en sus dominios favoritos (juegos de mesa lógicamente complejos como el ajedrez y el Go) y ha superado los algoritmos RL sin modelos de última generación en los entornos de Atari.La capacidad de MuZero para aprender un modelo de su entorno y utilizarlo para planificar con éxito demuestra un avance significativo en el aprendizaje por refuerzo y la búsqueda de algoritmos de propósito general. Sus predecesores ya se han aplicado a una variedad de problemas complejos de diversos sectores como la química, física cuántica o logística. Este avance puede allanar el camino para abordar nuevos desafíos en robótica, sistemas industriales y otros entornos complicados del mundo real donde no se conocen las "reglas del juego''.Una forma util de entender este articulo es comparar MuZero con enfoques mas simples de aprendizaje por refuerzo. Los metodos tabulares almacenan explicitamente valores para estados conocidos, mientras que MuZero aprende una representacion interna que solo necesita ser util para planificar. Por eso conecta bien con la introduccion al aprendizaje por refuerzo, las soluciones tabulares y Google Research Football.
Bibliografía
1.Titulo
Mastering atari, go, chess and shogi by planning with a learned model
Autor
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and others
Publicacion
Nature
2.Titulo
List of shogi software
Autor
Publicacion
Wikipedia
3.Titulo
Human-level control through deep reinforcement learning
Autor
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Rusu, Andrei A and Veness, Joel and Bellemare, Marc G and Graves, Alex and Riedmiller, Martin and Fidjeland, Andreas K and Ostrovski, Georg and others
Publicacion
nature
4.Titulo
Aprendizaje por refuerzo
Autor
Publicacion
Wikipedia
6.Titulo
MuZero: Mastering Go, chess, shogi and Atari without rules
Autor
Publicacion
Deepmind