Introducción a Neo4j. Ejemplos de consultas en grafos
Se quiere diseñar una base de datos en Neo4j con los datos proporcionados en las siguientes tablas, de manera que se pueda extraer información sobre la actividad de los estudiantes.
Nota 2026
Conserva las consultas siguientes como ejercicio practico de Cypher. La idea central sigue vigente: Neo4j modela datos conectados como nodos, relaciones y propiedades, y Cypher expresa recorridos con patrones como MATCH ... RETURN.
Lo que ha cambiado es el ecosistema alrededor. El manual actual de Neo4j trabaja con Cypher 25, y GQL ya es un estandar ISO para lenguajes de consulta de grafos. Para un proyecto nuevo, revisa tambien constraints, indices, autorizacion, estrategia de importacion y si los algoritmos de grafos o Graph Data Science forman parte real del caso de uso.
Neo4j tambien tiene ahora un contexto mas fuerte en AI/search: los indices vectoriales y las herramientas GraphRAG pueden combinar embeddings con relaciones del grafo. Tomalo como contexto util, no como motivo para usar grafos en cualquier caso. Neo4j encaja mejor cuando el valor de la consulta esta en recorrer relaciones, caminos, comunidades, dependencias o patrones de conexion similares a fraude.
Estudiantes matriculados.
| IdE | IdC | Título | Créditos | Profesor | Nombre estudiante |
|---|---|---|---|---|---|
| 201 | 101 | Filología románica | 7 | Sara Martínez | Maria Mestre |
| 201 | 102 | Griego moderno | 7 | Daniel Pérez | Maria Mestre |
| 202 | 106 | Teorías literarias | 3 | Juan García | Rodrigo Calvo |
| 203 | 103 | Literatura moderna | 10 | Amalia Sierra | Oriol Menezes |
| 203 | 105 | Fonética y morfología | 5 | Miguel Hernández | Oriol Menezes |
| 203 | 108 | Español moderno | 10 | Isabel Sanz | Oriol Menezes |
| 204 | 101 | Filología románica | 7 | Sara Martínez | Carlo Berruzo |
| 205 | 103 | Literatura hispano-americana | 5 | Paloma Sánchez | Sofia Canyadell |
| 205 | 104 | Literatura hispano-americana | 5 | Paloma Sánchez | Sofia Canyadell |
| 205 | 108 | Español moderno | 10 | Isabel Sanz | Sofia Canyadell |
| 206 | 106 | Teorías literarias | 3 | Juan García | Marina Perez |
| 206 | 107 | Lingüística general | 3 | Samuel López | Marina Perez |
| 207 | 107 | Lingüística general | 3 | Samuel López | Arianna Ruiz |
| 208 | 104 | Literatura hispano-americana | 5 | Paloma Sánchez | Naiara Zapico |
Nota de los estudiantes examinados.
| Créditos | Nota Exam | IdE | Título | Profesor |
|---|---|---|---|---|
| 7 | B | 201 | Filología románica | Sara Martínez |
| 7 | B | 201 | Griego moderno | Daniel Pérez |
| 3 | C | 202 | Teorías literarias | Juan García |
| 10 | A | 203 | Literatura moderna | Amalia Sierra |
| 5 | B | 203 | Fonética y morfología | Miguel Hernández |
| 10 | A | 203 | Español moderno | Isabel Sanz |
| 7 | B | 204 | Filología románica | Sara Martínez |
| 10 | C | 205 | Literatura moderna | Paloma Sánchez |
| 5 | B | 205 | Literatura hispano-americana | Paloma Sánchez |
| 10 | A | 205 | Español moderno | Isabel Sanz |
| 3 | B | 206 | Teorías literarias | Juan García |
| 3 | B | 206 | Lingüística general | Samuel López |
| 3 | A | 207 | Lingüística general | Samuel López |
| 5 | C | 208 | Literatura hispano-americana | Paloma Sánchez |
1. Argumentar cuál es la mejor forma de estructurar la información proporcionada para la segunda tabla, es decir, presentar las notas de los estudiantes examinados.
En las condiciones expuestas, deberemos implementar un árbol multinivel de forma que cada nivel sirva para filtrar por la información que interesa. En el nivel más alto de la jerarquía aparecerán nodos de tipo “Curso” que representan a los diferentes cursos ofertados. En el siguiente nivel aparecerán nodos de tipo “Estudiante” representando a los estudiados que han sido evaluados en los cursos relacionándose mediante la relación “EXAMINADO”. Por último, se consideran nodos de tipo “Profesor” que representan a los profesores que han impartido los cursos relacionándose mediante la relación “FUE_IMPARTIDA”. Un ejemplo de esta estructura es la siguiente imagen: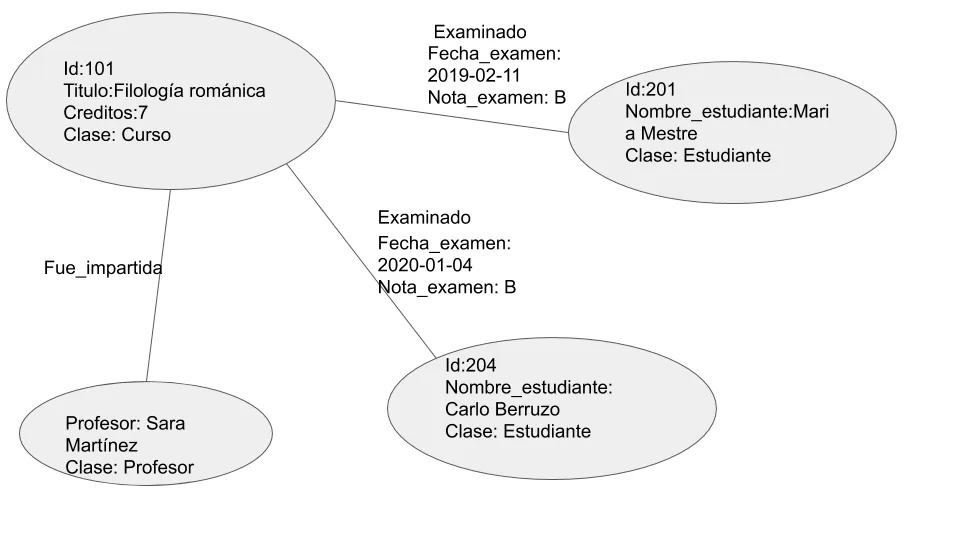
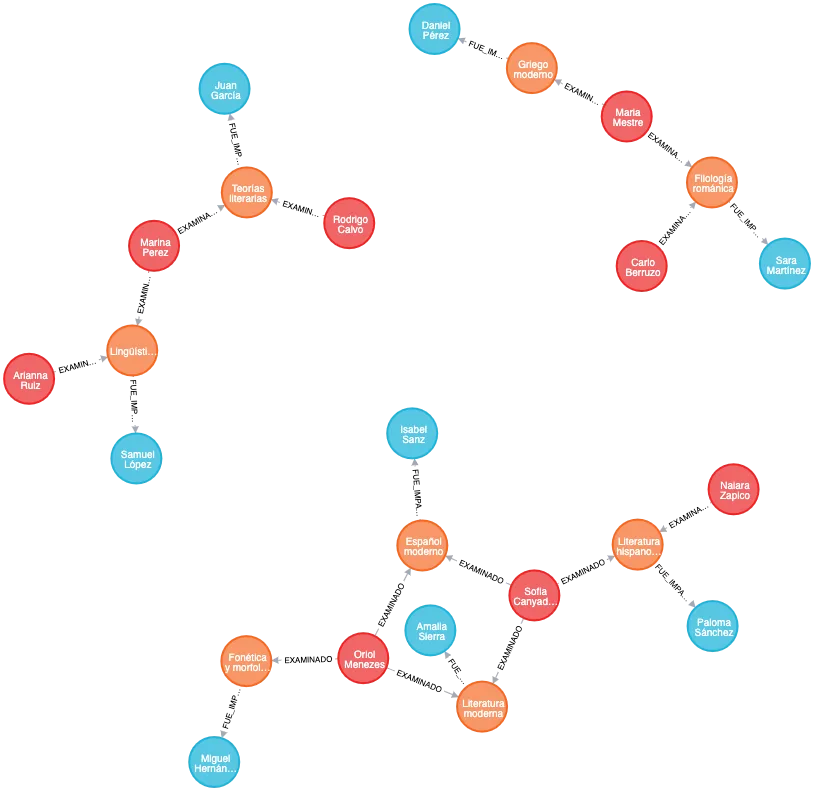
2. Creamos la base de datos mediante sentencias en Cypher, siguiendo la propuesta planteada en el apartado 1 . Se deberán mostrar las queries y el resultado obtenido.
3.Resolver las siguientes consultas:
- Para todos los estudiantes que obtuvieron una nota ‘C’ en algún curso de 5 créditos, listar el nombre del estudiante, el título del curso y el nombre del profesor del curso En este caso tenemos que buscar todos los estudiantes que han sido examinados en algún curso y han obtenido una 'C'. Una vez obtenida esta información, obtenemos el profesor que ha impartido el curso.
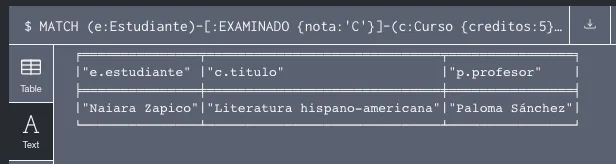
3 Respuesta a la primera consulta - Visualizar los nodos y relaciones de los estudiantes que cursaron “Griego moderno” o “Español moderno” en 2019 En este apartado tenemos que buscar todos los estudiantes que han sido examinados en un curso. En la relación, únicamente debemos escoger los usuarios examinados en el año 2019 para los cursos “Griego moderno” o “Español moderno”.
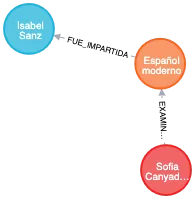
4 Estructura en grafo de la respuesta 5 Respuesta a la segunda consulta
4 Twitter
Considera la guía “Analyzing Twitter with Neo4j” que describe la implementación de una base de datos en Neo4j.- Obtener el usuario relevante que ha escrito el geolocated tweet con el mayor número de replies. Listar el userName y el número de replies. Básicamente voy ha buscar todas las respuestas de los tweets geolocalizados. Una vez obtenido, he buscado aquellos tweets escritos por usuarios relevantes. Por último, devuelvo su nombre de usuario junto con la cantidad de tweets creados. Al estar los tweets ordenados, el primer valor será aquel que tenga el mayor número de replies y, por lo tanto, el valor que necesito devolver.
El resultado obtenido al ejecutar la consulta es: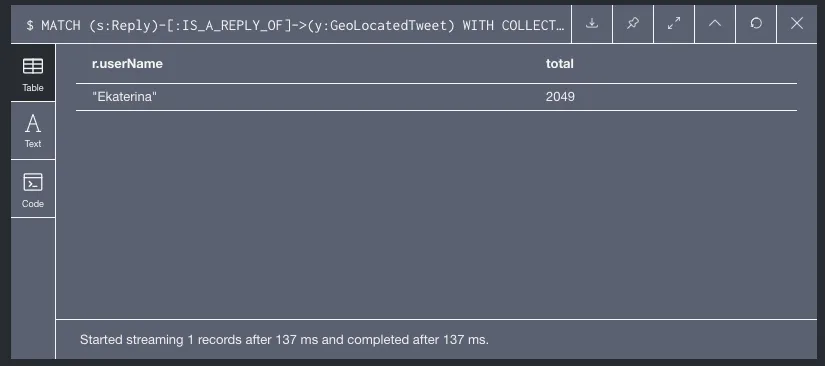
6 El usuario más relevante que ha escrito el geolocated tweet con el mayor número de replies. Listar el userName y el número de replies. - Obtener el número de Geolocated tweets escritos desde barcelona y con la palabra “Buenafuente” en el texto. En esta consulta hemos utilizado los tweets geolocalizados y su relación con Location. Únicamente utilizaremos todos aquellos localizados desde Barcelona y que en la variable text contenga 'Buenafuente'.
El resultado obtenido al ejecutar la consulta es: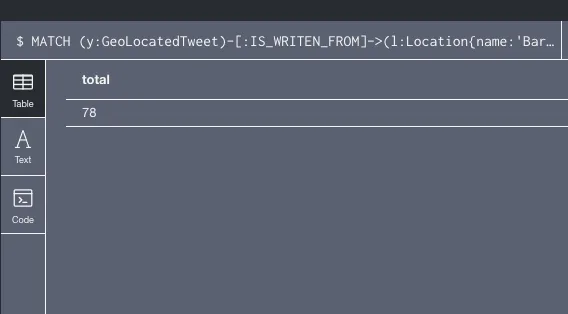
7 Número de Geolocated tweets escritos desde barcelona y con la palabra “Buenafuente” en el texto - Obtener la lista de usuarios relevantes de Barcelona con followers de Madrid. Ordenar la lista por número de followers y listar sólo el segundo. Lo más importante de esta consulta es utilizar skip y limit para poder obtener el segundo resultado más elevado. Por lo demás, únicamente he buscado usuarios relevantes de Barcelona que tengan una relación de FOLLOWS con un usuario relevante de Madrid.
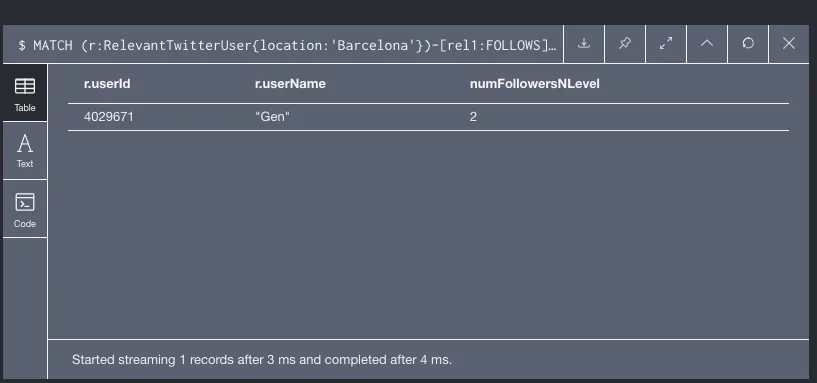
8 Usuarios relevantes de Barcelona con followers de Madrid. - Calcular el ratio entre el número de twitterUsers en castellano y ingles Para conseguir mi objetivo he contado la cantidad de usuarios que tienen el perfil en ingles (numin) y castellano (numes). Posteriormente he obtenido la proporción que es 2 a 1 a favor del ingles.
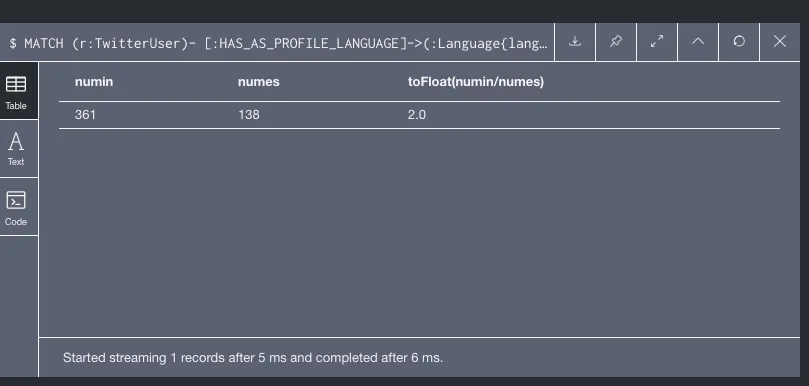
9 Ratio entre el número de twitterUsers en castellano y ingles.