2. Searching the Web
Enunciado 1 Como introducción a los buscadores Web, os proponemos la lectura de este artículo de Arvind Arasu, Junghoo Cho, Hector García-Molina, Andreas Paepcke y Sriram Raghavan titulado Searching the Web que podeís encontrar
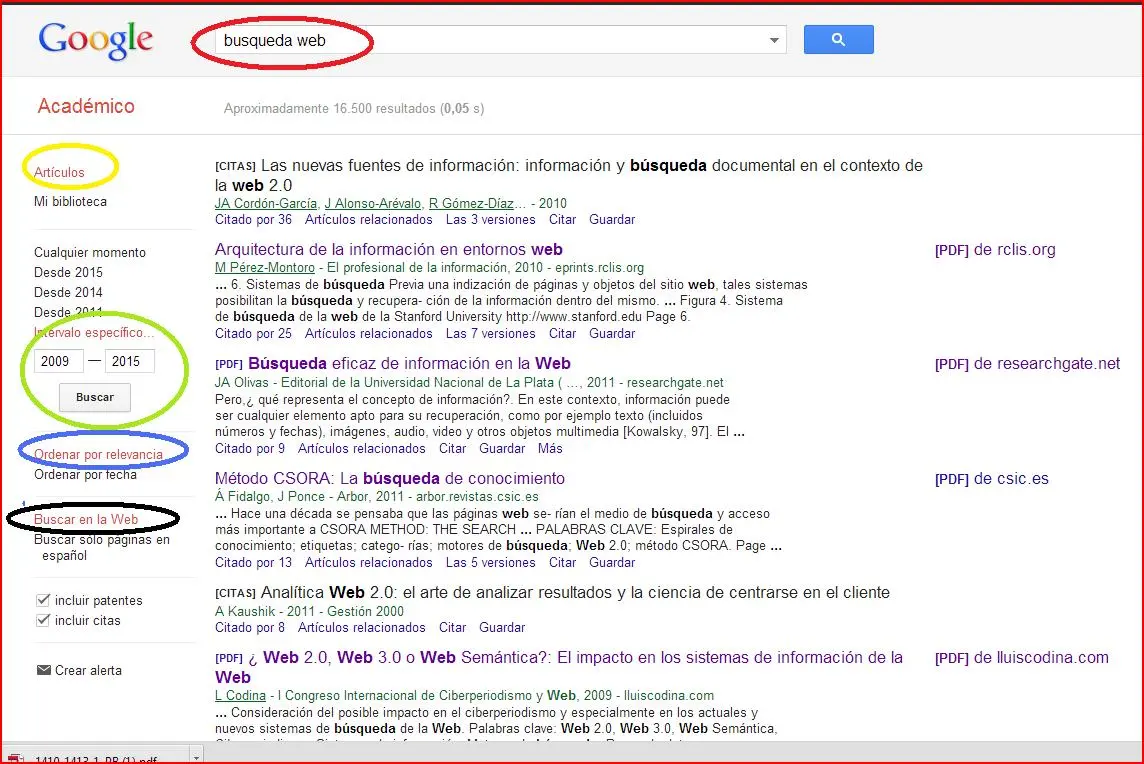
aquí. Una vez leido este articulo, debéis seleccionar en scholar.google.com tres artículos recientes (preferiblemente desde 2009) que lo citen y que tengan el mayor impacto posible, y a partir de ellos discutir tres factores en los que la investigación actual se sitúa mucho más allá de lo que se plantea en el artículo original.
Después de realizar la lectura del artículo Searching the web he seleccionado los tres artículos siguientes, que lo citan en sus referencias:
Resumen: En este articulo se analiza los problemas actuales que existen en los motores de búsqueda para indexar, analizar y buscar nueva información en la Deep Web y Hidden Web. Estos términos, muy utilizados ultimamente se refieren a 3 tipos distintos de Internet que existen actualmente que son:
- Internet global: Definiremos ésta como aquella Red de información libre y gratuita que es accesible teóricamente mediante la interconexión de ordenadores. La forma de acceso se realiza mediante programas navegadores, Chats, mensajería o intercambio de protocolos (FTP, P2P).
- Internet invisible: Responde a todos aquellos contenidos de información que están disponibles en Internet pero que únicamente son accesibles a través de páginas generadas dinámicamente tras realizar una consulta en una base de datos. Esta particular naturaleza les hace inaccesibles a los procesos habituales de recuperación de la información que realizan buscadores, directorios y agentes de búsqueda. Pero podemos acceder a las mismas mediante nuestras habituales herramientas de navegación, correo, etcétera. La única condición es saber exactamente la dirección de acceso (URL o FTP)
- Internet oscuro: Se define como los servidores o host que son totalmente inaccesibles desde nuestro ordenador. Según un estudio de la compañía Arbors Networks esta situación sucede en el 5 % de los contenidos globales de la Red. La causa principal (78% de los casos) se debe a zonas restringidas con fines de seguridad nacional y militar. El porcentaje restante, (22% obedece a otros motivos: configuración incorrecta de routers, servicios de cortafuegos y protección, servidores inactivos y finalmente “secuestro" de servidores para utilización ilegal.
En el articulo, nos proponen nuevos métodos para implementar Crawlers más eficientes que permitan realizar búsquedas de contenidos situados en los dos últimos tipos de interet. Para ello se han basado en algoritmos utilizados en Web Mining y clasificación genética.
Resumen: La World Wide Web es una gran fuente de información llena de hipervínculos a contenidos de hipertexto. Los motores de búsqueda utilizan rastreadores web para recoger estos documentos desde la web con el propósito de almacenamiento e indexación. Sin embargo, muchos de estos documentos contienen información dinámica que se cambia a diario, semanal, mensual o anual y por lo tanto tenemos que actualizar el almacenamiento del lado del motor de búsqueda para que la información más reciente se pone a disposición del usuario. Un rastreador incrementales visita la web varias veces después de un intervalo de tiempo específico para la actualización de su colección. En este trabajo de regular la frecuencia revisitación un nuevo mecanismo y se está proponiendo una arquitectura novedosa para crawler incrementales.
Resumen: La parte más difícil de un rastreador web es descargar contenidos al ritmo más rápido posible para el ancho de banda permitido y al mismo tiempo ir tratando la información descargada sin dejar ningún momento muerto el programa. El sistema de rastreo web escalable implementado en el articulo , llamado WebTracker, ha sido diseñado para responder a este desafío. Según el articulo, al distribuir el software se puede disminuir los recursos utilizados manteniendo el mismo ritmo de resultados. WebTracker tiene un servidor Crawler Central y administra todos los nodos. En cada nodo hay un Crawler, que ejecuta un programa de descarga y gestiona los contenidos descargados y los analiza. Mientras el crawler Server asegura sincronizado operaciones distribuidas del sistema.
2.1 Resumen y conclusión del artículo Searching the Web
En el artículo Searching the web, se tratan diferentes puntos sobre el rastreo web, el almacenamiento de páginas, la indexación y el uso de diferentes técnicas para el diseño e implementación de una serie de componentes.
Introducción
Los autores nos cuentan los distintos desafíos que se encuentran a la hora de realizar la creación de buenos motores de búsqueda, enumeran una serie de técnicas útiles. Concretamente, nos detallan las técnicas de IR (Information Retrieval), las cuales sirven para recuperar información de colecciones pequeñas, como por ejemplo, artículos de periódicos y catálogos de libros en bibliotecas.
Sin embargo, estas técnicas de IR, no son válidas para la web, ya que ha sufrido un aumento de volumen considerable y utilizarla supondrian demasiados recursos, así que trata de mostrarnos técnicas nuevas como la indexación que produce escalabilidad a la hora de realizar rastreos web, el uso de técnicas de discriminación de webs con contenido irrelevante.También tiene en cuenta si la página es referida por otras páginas con unos términos concretos, lo que denotaría que esa página es importante con esos términos concretos.
Entonces nos explican el funcionamiento de los crawlers, que son pequeñas aplicaciones encargadas de rastrear un repositorio de páginas web, observando los cambios que hay en ellas, incluyendo nuevas páginas que encuentran, etc. A través de complejos algoritmos de rastreo. Cuando el rastreador completa un ciclo, ya sabe qué páginas son las que debe rastrear y cuáles no. La optimización de recursos se consigue gracias a la indexación.
Rastreo de páginas web
En el segundo punto del artículo, nos resume las distintas funciones que debe hacer el rastreador a la hora de recoger la información de todas las webs. En primer lugar, las páginas pasan por un módulo de rastreo que recupera las páginas para un análisis posterior por el módulo de indexación. A través de un conjunto de webs que son recibidas, se asigna una prioridad a cada una de ellas para que sean analizadas.
Un tema que también es tratado de manera bastante amplia en el artículo es el método de selección de páginas, en el cual tratan distintos modelos de importancia, por popularidad, interés, ubicación , etcétera. Unido a esto, vienen los modelos de rastreo, concretamente trata sobre dos: rastreo y parada, rastreo y parada con umbral. Además, la actualización de las páginas, o la "frescura" de los enlaces que hay en el buscador y estrategias de actualización son otros temas derivados en este punto.
Almacenamiento: Desafíos y repositorios.
En el tercer punto del artículo, trata sobre la escalabilidad que debe haber en los repositorios de almacenamiento de colecciones grandes páginas web.
Esto conlleva una serie de desafíos, ya que, el repositorio gestiona una gran colección de objetos de datos (en este caso páginas web), similar a sistemas de ficheros o a bases de datos. Surgen problemas como: escalabilidad, acceso dual, grandes actualizaciones a granel y páginas obsoletas.
Indexación: Estructuras de índices, desafíos, particionamientos, sistemas de indexación de textos.
Existe un módulo de análisis que crean una variedad de índices. El análisis produce enlaces, índices de texto e índices de utilidad. Las etiquetas html H1, H2 o b facilitan el trabajo a los analizadores para saber qué información es la más importante en una web.
Con los índices lo que se crean son unos grandes grafos que poseen nodos y enlaces muy importantes, que facilitan la comprensión de textos por parte de los rastreadores
Ranking y análisis de enlaces: PageRank, algoritmos HITS y otras técnicas.
Al ser tan grande internet, la manera de evaluar qué web es más importante, es complejo. Así que se crearon distintos algoritmos que evalúan la importancia de una página web en función de diferentes parámetros.
Por un lado está el PageRank, que tiene variaciones: el PR Simple y el PR Práctico. El PageRank depende de la importancia de las webs, y los enlaces que existen desde ella y hacia ella, a más importante sea una web, más PageRank transmite a las webs que él mismo enlaza. El otro algoritmos, HITS, se encarga de identificar, dada una consulta, un conjunto de páginas web naturales o páginas web de autoridades.
Conclusiones finales en comparación con el primer artículo Searching the Web.
Después de buscar tres referencias más actuales sobre la búsqueda en la web y que además referencien este artículo, he podido observar los siguientes detalles:
- Velocidad, reducción de recursos y capacidad de almacenamiento: Tanto en el artículo que hemos tenido que leer, del año 2001, como en los 3 artículos más recientes que he seleccionado de scholar.google.com, he observado que dan una importancia suprema a la velocidad de rastreo, a la minimización de recursos a la hora de realizar estos rastreos (intentar consumir poco ancho de banda, poca CPU y poca memoria RAM, distribuyendo procesos, etc) e intentar también tener el mayor número de información en el menor espacio posible. En los artículos, cuentan una serie de algoritmos de mejora de rastreo, que han conseguido optimizar al máximo la velocidad, los recursos y sobre todo el almacenamiento.
- Problemas en los rastreos: En los procesos de búsqueda de contenido web valido como una respuesta a un usuario.
- El PageRank o la importancia de las webs: Hace unos años, se inventó un algoritmo para calcular la importancia de un sitio web, el cual estaba basado en la importancia de las webs que te enlazaban, sobre todo. Esto a lo largo de los años ha cambiado, y el PageRank, no es actualmente el valor que más observa un rastreador para calcular su importancia en internet, ya que, se comenzaron a crear una serie de modas que fomentaron el spamming, provocando que los buscadores bloquearan este tipo de webs y las penalizaran en cuanto a posiciones en google se refiere. Ahora se tienen más en cuenta otros factores como la pureza del código (si cumple estándares css, w3c, xhtml... etcétera) además de que esté correctamente redireccionado con un buen fichero htaccess.