Comparación de la utilidad del análisis automático de polaridad reputacional respecto al análisis de sentimientos para predecir valores de bolsa
Aunque el análisis de sentimiento es la herramienta de Procesamiento del Lenguaje Natural más utilizada para la gestión de reputación online, se ha demostrado en el contexto de la campaña de evaluación RepLab que los sentimientos de un texto que habla de una entidad y sus implicaciones reputacionales para esa entidad son cosas diferentes; de hecho, la mayoría de los textos con implicaciones reputacionales son polar facts, es decir, información factual sin sentimientos explícitos.
En esta Tesis de fin de Máster, nuestro objetivo es comparar la utilidad del análisis automático de polaridad reputacional respecto al análisis de sentimientos para predecir valores de bolsa, bajo la hipótesis de que el análisis reputacional debería tener una relación más directa con la cotización y, por tanto, ser un mejor predictor de su valor bursátil. Para nuestra experimentación hemos seleccionado el bitcoin (un valor altamente volátil y por tanto un reto desde el punto de vista de los modelos predictivos) y Twitter como fuente textual, por ser una de las redes sociales en las que se puede recolectar datos de forma más sencilla y, sobre todo, por su inmediatez, que es necesaria a la hora de establecer correlaciones temporales con un valor muy fluctuante como es la cotización del Bitcoin.
Como no existía ningún dataset adecuado para nuestro objetivo, nuestra primera contribución ha sido desarrollar BitTweet, un dataset de tweets que mencionan bitcoin anotado manualmente respecto a sentimiento y polaridad reputacional y enlazado con la cotización del bitcoin. Las anotaciones manuales de este dataset nos permiten cuantificar la diferencia entre análisis de sentimiento y polaridad reputacional (algo que no había sido hecho previamente), evaluar modelos de predicción de sentimiento y polaridad reputacional, y evaluar modelos de predicción de valor bursátil a partir de tweets.
Nuestra segunda contribución ha sido la aplicación del estado del arte en Procesamiento del Lenguaje Natural (en particular, los contextual word embeddings en su implementación en el sistema BERT) a la estimación de la polaridad reputacional de los tweets y a la predicción de valores bursátiles, comparándola con el análisis del sentimiento. Nuestros resultados confirman nuestra hipótesis, mostrando que la polaridad reputacional es mejor predictor que el análisis de sentimientos. Estos resultados sugieren que los sistemas de análisis reputacional deberían reducir su dependencia del software de análisis de sentimientos y sustituirlo por un análisis directo de las implicaciones reputacionales de los textos.
Palabras clave
Bert, Polaridad Reputacional, Análisis de sentimiento, Python, Bitcoin
Alcance histórico y reproducibilidad
Este TFM analiza datos de Twitter y Bitcoin recopilados en 2019. Sus resultados describen ese dataset y diseño experimental; no son una señal actual de inversión. Para reproducirlos hacen falta la partición temporal, etiquetas, preprocesamiento, versiones de modelos y serie de mercado originales, además de vigilar cambios de distribución.
Indice
1. Introducción
En el primer capítulo se documentan cual es el contexto, la motivación del alumno, los objetivos propuestos al inicio del proyecto, así como la estructura de toda la memoria.
1.1. Reputación Online
La reputación online es un reflejo del prestigio de una persona, organización, marca, etc. en Internet. Esta percepción no está bajo el control de un sujeto o una organización, sino que es el resultado de un conjunto de conversaciones, opiniones, sucesos y artículos compartidos en diferentes medios sobre una entidad determinada. Ahora bien, aunque la aparición de Internet representa una nueva oportunidad de comunicación entre las entidades y sus usuarios, la diversidad de medios (blogs, redes sociales, webs, etc.) junto con la gran cantidad de información complican la capacidad de los analistas para cuantificar esta percepción.
Para poder conocer la reputación online de una marca o entidad, el analista de debe filtrar este flujo de datos con el objetivo de encontrar la información más relevante y clasificarla acorde a sus implicaciones positivas, neutrales o negativas y a su impacto potencial.
Aunque el análisis de sentimientos es la herramienta de Procesamiento del Lenguaje Natural más utilizada para la monitorización de la reputación online, se ha demostrado que los sentimientos de un texto y sus implicaciones reputacionales para esa entidad son cosas diferentes; de hecho, la mayoría de los textos con implicaciones reputacionales son polar facts, es decir, información factual sin sentimientos explícitos. Por supuesto, medir la polaridad reputacional de un texto es más complicado cuando el documento no expresa implícitamente una reputación positiva o negativa sobre el tema analizado.
Invertir recursos en este tipo de análisis puede proporcionar a las entidades aplicaciones positivas, por ejemplo, para obtener datos a partir de opiniones no estructurados sobre un servicio o producto. Un uso real de la aplicación del análisis de la polaridad reputacional lo podemos encontrar en cualquier empresa que tenga Twitter u otras cuentas en redes sociales donde se reciban comentarios. Obviamente, para una entidad es un mal negocio dejar comentarios negativos sin respuesta durante demasiado tiempo, por lo tanto, una aplicación que permita identificar tweets con reputación negativa puede darles una forma rápida de encontrar y priorizar a estos clientes descontentos.
1.2. Análisis de sentimientos vs polaridad reputacional
Como hemos introducido en la sección 1.1. Reputación Online , los sentimientos de un texto y sus implicaciones reputacionales para esa entidad son cosas diferentes. Por ese motivo, en esta sección es necesario exponer que es el Análisis de sentimientos, en que se diferencia del análisis de la polaridad reputacional y cómo podemos utilizar sus avances en el proyecto.
El análisis de sentimientos, tal y como se conoce actualmente, es el proceso de determinar si un texto expresa sentimientos o emociones. Aunque puede consistir en la especificación de qué emociones se expresan y con qué intensidad (valencia), el análisis más sencillo - y más habitual - consiste simplemente en determinar sin un texto expresa sentimientos positivos, negativos o neutrales (polaridad del sentimiento).
Por ejemplo, las palabras "buen" y "excelente" se tratarían igual en un enfoque basado en polaridad, mientras que "excelente" se trataría como más positivo que "bueno" en un enfoque basado en valencia.
Para determinar si estas palabras son positivas o negativas (o en qué medida), los desarrolladores de estos enfoques necesitan a un grupo de personas que las califiquen manualmente para cada tipo de contexto, lo que obviamente es bastante costoso y requiere mucho tiempo. Además, el léxico debe tener una buena cobertura de las palabras típicas en el contexto de estudio, de lo contrario no será muy preciso. Por otro lado, cuando hay un buen ajuste entre el léxico y el objetivo a estudiar, el análisis del sentimiento es muy preciso y, además, devuelve resultados rápidamente incluso en grandes cantidades de texto.
Como hemos comentado, el trabajo para generar los léxicos es bastante costoso y requieren mucho tiempo de producción, por lo tanto, la frecuencia de actualización no es muy elevada. Esto significa que los léxicos carecen de la última jerga actualizada y esto puede suponer un problema. En la figura 1 se puede ver un ejemplo de esta situación, ya que el usuario muestra su opinión de descontento a través de una jerga muy actual (cuadros azules) utilizando signos de puntuación múltiples, acrónimos y un emoticono. Si el análisis no tiene en cuenta estas expresiones, este tweet negativo se clasificaría como neutral por el resto del contenido.
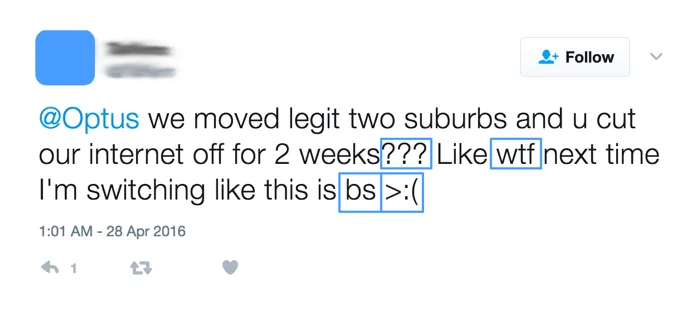
Cuando un texto tiene una polaridad de sentimiento negativa y hace referencia a la entidad de interés, es posible que tenga implicaciones negativas para su reputación. Por ejemplo, "Estoy harto del servicio de venta online de Renfe" expresa un sentimiento negativo (hartazgo) respecto a la compañía Renfe, y por tanto puede afectar negativamente a su reputación. Esto hace que el análisis de sentimientos se aplique de forma habitual para medir el estado de opinión respecto a una compañía, producto, organización, etc.
Como hemos comentado en la sección 1.1 , la reputación de una entidad puede verse afectada por noticias o hechos donde no se exprese un sentimiento. La aprobación de una ley, la implementación de una mejora técnica o incluso desastres económicos como los vividos en Venezuela deben etiquetarse de forma diferente desde el punto de vista de la reputación al del sentimiento. Este punto se expondrá más adelante, en la sección 3.2 donde se tratarán estas diferencias con ejemplos. Aquí daremos sólo un ejemplo: "La compañía X paga un 1\% de sus beneficios en impuestos" es una expresión factual, sin ningún sentimiento asociado; sin embargo, este hecho sugiere algún tipo de fraude o ingeniería fiscal, y por tanto tendrá consecuencias negativas inmediatas sobre la percepción de la compañía por parte de la opinión pública. A este tipo de expresiones se las conoce como "polar facts", y son muy frecuentes en el contexto de la reputación online.
Otra diferencia entre polaridad de sentimiento y análisis reputacional es que, en ocasiones, un sentimiento negativo puede implicar una polaridad reputacional positiva, y viceversa. Por ejemplo, "Estoy muy triste por el fallecimiento de X" es un sentimiento negativo con implicaciones positivas para X.
Aunque la polaridad reputacional es sustancialmente diferente del análisis de sentimientos, en el artículo Sentiment propagation for predicting reputation polarity [2] se muestra como las dos tareas tienen puntos en común que se pueden aprovechar y, por lo tanto, se debe analizar. Como hemos comentado anteriormente, crear un nuevo modelo para el análisis automático de la polaridad reputacional supondría un gran esfuerzo en recursos y tiempo, por lo tanto, podemos aprovechar las investigaciones previas en el análisis automático del sentimiento con el objetivo de adaptarlo para la detección polaridad reputacional. En cierta medida, la polaridad reputacional está relacionada con el análisis de sentimiento y, por lo tanto, los trabajos previos en este campo nos serán útiles para el estudio de polaridad reputacional. Siguiendo este punto de vista, nos encontraremos dos campos que pueden aportar información para la investigación:- Léxico. Cada palabra que expresa sentimiento en un documento es un indicador de información. Por lo tanto, sería posible encontrar listados con términos de opinión, consultas o listados adaptados al tema analizado que podríamos utilizar.
- Por características. El sentimiento también se puede obtener de las características sintácticas del texto a través de algoritmos supervisados o semisupervisados.
Un poco más adaptado a la sociedad actual y fuera de estas dos grandes categorías hay estudios que utilizan los comentarios en las redes sociales o las reacciones de los usuarios para conocer el sentimiento de un texto.
Una vez realizada esta breve introducción, conviene entender y analizar una solución léxica de análisis del sentimiento para adaptarla a la polaridad reputacional. Un ejemplo válido sería adaptar el algoritmo expuesto en el artículo Algorithmic trading of cryptocurrency based on Twitter sentiment analysis [3] con el objetivo de detectar el sentimiento del documento a través de un diccionario de palabras donde se especifique la polaridad del sentimiento (positivo o negativo) a un determinado tema. El resultado de este mecanismo es una puntuación basada en el número de palabras con sentimiento contenidas en el documento.
Esta definición se expresaría matemáticamente de la siguiente forma:
- Polaridad(d) es la polaridad del sentimiento para el documento d expresada en los valores .
- d Es la puntuación del documento d basada en la suma de la puntuación de sus términos
- opinion(t) es la puntuación del término según el diccionario.
Para mejorar este enfoque, se pueden proponer diferentes mejoras como por ejemplo reclasificar los términos que estén catalogados como neutrales y utilizar estas palabras para aumentar el diccionario o propagar el sentimiento entre documentos con un elevado grado de términos similares.
Es más, si modificamos el léxico utilizado para clasificar los términos y los catalogamos acorde a su polaridad reputacional, obtendríamos un nuevo algoritmo capaz de predecir de forma automática la polaridad de un texto. Además, se podría implementar un método supervisado para descubrir palabras que indiquen esta característica. Este enfoque está basado en Pointwise Mutual Information ( PMI ) expuesto en la obra Word association norms, mutual information, and lexicography [4] dónde se asigna a cada uno de los términos t un valor PMI para cada una de las tres categorías: positiva, neutral y negativas. Para obtener esta puntación tenemos que realizar el siguiente calculo:
- c(t,positivo) es la frecuencia del término t en los documentos positivos.
- N es el número total de palabras en el corpus.
- c(t) es la frecuencia del término t en el corpus cuando.
- c(positivo) es el número de términos positivos en el documento.
El PMI de los términos negativos y neutrales se calculará de la misma forma. La valoración final será el valor más alto entre las clases de los diferentes términos.
Este ejemplo es útil para entender que es y cómo se puede medir la polaridad reputacional en un texto, pero para innovar en el proyecto se requiere utilizar técnicas más modernas y eficientes aplicadas a la lingüística.
1.3. Objetivos
El objetivo de la tesis es comparar la utilidad del análisis automático de polaridad reputacional respecto al análisis de sentimientos para predecir valores de bolsa, bajo la hipótesis de que el análisis reputacional debería tener una relación más directa con la cotización y por tanto ser un mejor predictor de su valor bursátil.
Como hemos comentado al principio del capítulo, para llevar a cabo este objetivo es necesario aprender a filtrar un flujo de datos para encontrar la información más relevante con el objetivo de poderla clasificar acorde a sus implicaciones positivas, neutrales o negativas y correlacionar ese sentimiento o polaridad con la evolución bursátil de un valor.
Como no existía ningún dataset adecuado para nuestro propósito, nuestro primer objetivo ha sido desarrollar un dataset de documentos anotados manualmente respecto a sentimiento y polaridad reputacional y enlazado con la cotización de un valor bursátil. Las anotaciones manuales de este dataset nos permitirán cuantificar la diferencia entre análisis de sentimiento y polaridad reputacional, evaluar modelos de predicción de sentimiento y polaridad reputacional, y evaluar modelos de predicción de valor bursátil.
El segundo objetivo es analizar el estado del arte en Procesamiento del Lenguaje Natural con el objetivo de encontrar un algoritmo que nos permita cuantificar la polaridad reputacional de un documento y a la predicción de valores bursátiles, comparándola con el análisis del sentimiento.
1.4. Metodología
Para cumplir los objetivos expuestos en la sección 1.3 , el primer paso es escoger el valor bursátil a predecir. En este punto, se escogió Bitcoin, un sistema de moneda digital peer-to-peer programado en código abierto [5] y considerado como una alternativa a las monedas estándar. En la sección 1.4.1 se explicarán las características de la criptomoneda, así como el principal motivo de su elección.
A continuación, a partir del estudio de varios artículos basadas en algoritmos bayesianos y machine learning aplicados a la predicción bursátil, se ha podido llegar la conclusión que, para predecir la volatilidad de un valor bursátil se debe analizar su correlación con un conjunto de características entre las que pueden estar su valor económico, datos macroeconómicos o sus repercusiones sociales entre otros. Un ejemplo, se puede ver una muestra esta correlación es el articulo Exploring the determinants of Bitcoin's price: an application of Bayesian Structural Time Series [6] donde se expone la relación que existe entre la aparición de nueva legislación para el Bitcoin y un aumento de precio.
Esta afirmación ha afectado al siguiente punto de la metodología, la fuente de datos a utilizar. Del estado del arte hemos podido deducir como la red social Twitter puede ser una fuente de información perfecta sobre una entidad, ya que su formato conciso y la facilidad para extraer documentos en tiempo real ha permitido predecir la evolución del mercado. Por ejemplo, Colianni, Stuart and Rosales, Stephanie and Signorotti, Michael lo exponen en su obra Algorithmic trading of cryptocurrency based on Twitter sentiment analysis [3] donde, a partir de dos distribuciones creadas utilizando los tweets recopilados en su experimento, han conseguido predecir la evolución del mercado con el suficiente éxito como para confirmar la correlación entre el valor y el sentimiento de los usuarios en esa red social. Otro ejemplo lo podemos encontrar en The Information of Spam [8] donde demuestra que los tweets considerados como spam contienen información que ayuda a predecir la tendencia de los mercados, es decir, Anderson, Sawyer C afirma que este tipo de información considerado inútil para la mayoría de la humanidad puede tener información relevante para realizar estimaciones.
El siguiente punto en la metodología más importante fue analizar los algoritmos que existen en este momento para el análisis del lenguaje, así como conocer qué tipo de usuarios está destinada la entidad, sus intenciones y la forma de obtener información sobre ellos, es decir, analizar como poder medir la polaridad reputacional de un tweet. Tener toda esa información nos permitirá poder clasificar sus opiniones de forma correcta.
Para poder relacionar esta información con la entidad y su evolución económica es necesario realizar una investigación sobre el campo del Machine Learning aplicado a la interpretación de textos. Aunque el análisis de la polaridad reputacional es sustancialmente diferente al de sentimiento, según Sentiment propagation for predicting reputation polarity [2] las dos tareas tienen puntos en común que se pueden aprovechar. Para ello en el siguiente apartado de la metodología analizaremos las técnicas de Procesamiento del Lenguaje Natural (PLN), la polaridad reputacional y el sentimiento para valorar la mejor solución. Más exactamente, se utilizará BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [9], el nombre que se le ha otorgado a uno de los más avanzados modelos de procesamiento de textos que existen y explicado en la sección sobre Bert.
Escogido el algoritmo a implementar, el documento continuará exponiendo la importancia no del sentimiento sino de la reputación de la entidad. Por ejemplo, en la obra Exploring the determinants of Bitcoin's price: an application of Bayesian Structural Time Series [6] se comprueba cómo existe una relación positiva entre la nueva legislación de los países sobre el Bitcoin y su aumento de precio, es decir, afirma que la reputación de la moneda es un factor que afecta a la criptomoneda. Por supuesto, una nueva legislación no posee un sentimiento en sí mismo, por lo tanto, utilizar las técnicas y no demostraría esta afirmación, se deben encontrar nuevas técnicas que confirmen esta relación de forma empírica.
Como no existía ningún dataset adecuado para nuestro objetivo, se ha tomado la decisión de desarrollar BitTweet , un dataset de tweets que mencionan Bitcoin anotado manualmente respecto a sentimiento y polaridad reputacional y enlazado con la cotización del bitcoin. Las anotaciones manuales de este dataset nos permiten cuantificar la diferencia entre análisis de sentimiento y polaridad reputacional (algo que no había sido hecho previamente), evaluar modelos de predicción de sentimiento y polaridad reputacional, y evaluar modelos de predicción de valor bursátil a partir de tweets.
Para terminar, se ha utilizado la estimación de la polaridad reputacional de los tweets obtenida de BERT y la predicción de valores bursátiles para compararla con el análisis del sentimiento. Para validar las implementaciones y comparar su acierto, se utilizado como referencia un modelo ya entrenado llamado VADER (Valence Aware Dictionary and sEntiment Reasoner) ( https://github.com/cjhutto/vaderSentiment ). Esta librería es una herramienta de análisis de sentimientos basada en reglas y léxico que está específicamente en sintonía con los sentimientos expresados en las redes sociales que nos permitirá comparar y validar los resultados obtenidos por BERT.
1.4.1 Bitcoin
Como ya se ha comentado, Bitcoin es un sistema de moneda digital peer-to-peer programado en código abierto [Bitcoin: A peer-to-peer electronic cash system] y considerado como una alternativa a las monedas estándar. Utiliza un protocolo criptográfico para controlar la creación y transferencia de dinero, asegurando que conserva su valor e impidiendo ser doblemente gastado. Se crea y se transfiere sin la necesidad de una autoridad central de gobierno, utilizando recursos computacionales al alcance de cualquier usuario y transfiriéndose directamente de una cuenta a otra utilizando algoritmos criptográficos.
Las criptomonedas tienen una serie de beneficios sobre las divisas tradicionales, ya que no existe la necesidad de un tercero de confianza. Actualmente, el comercio en las monedas de "papel" se basa en la confianza emitida por instituciones financieras que actúan como reguladores en los procesos de pago. Las debilidades inherentes a un modelo basado en el fideicomiso hacen que los costos de transacción aumenten, ya que el tercero inevitablemente tiene que lidiar con las disputas y mantener la infraestructura para las transacciones. Esto hace que las microtransacciones electrónicas sean inviables, ya que los costos de realizar una transacción global representan un coste demasiado elevado para ciertas cantidades. Para evitar este problema han surgido las criptodivisas como Bitcoin, que nos ofrecen una solución basada en pruebas criptográficas para evitar la necesidad de confianza mutua y riesgo de doble gasto. Un propietario debe firmar digitalmente un hash de la transacción anterior y la clave pública del siguiente propietario, para permitir que el beneficiario reciba una firma que verifique la cadena de propiedad. [bitcoin_prediction#Bitcoin: planteamiento y protocolo]
Como divisa, Bitcoin consta de tres elementos fundamentales: las direcciones, el libro mayor de transacciones (o cadena de bloques) y la red. El balance de una cuenta, representada por una dirección, no es más que el sumatorio de sus transacciones entrantes (valor positivo) y salientes (valor negativo). La red es la encargada de verificar la legitimidad y viabilidad de las transacciones, es decir, que estas han sido emitidas por los legítimos propietarios de las cuentas y que ninguna cuenta envíe dinero del que no dispone. Aparte, el protocolo está pensado para no permitir la existencia de más de veintiún millones de bitcoins, estableciendo que la generación de esta se reduzca a la mitad cada aproximadamente cuatro años.
Al igual que con cualquier otra moneda, el valor de Bitcoin está sujeto a variación significativa en el tiempo, sin embargo, los aspectos que afectan el precio del Bitcoin difieren de aquellos que afectan a las monedas estándar. El valor de cualquier moneda está relacionado con cuánta gente quiere poseerla, pero como el Bitcoin no está vinculada a un producto en particular o emitida por una autoridad central, no tiene valor intrínseco. En todas las monedas criptográficas, los consumidores no están limitados por una autoridad central, sino sólo en la moneda que aceptará el interlocutor en una transacción. La utilidad de poseer bitcoins —nótese que Bitcoin hace referencia a la moneda y bitcoin a la unidad— para el consumidor está, por lo tanto, relacionada con la medida en que los mercados la adoptan como una forma válida de moneda.
Al igual que el resto de los mercados de divisas, en Bitcoin existe una zona de intercambio abierto que permite a los consumidores e inversores comprar y vender bitcoins. El precio al que se negocia el Bitcoin está relacionado con el valor percibido por el inversor ya que no le afectan los factores como la cantidad de productos importados y exportados o el respaldo de los organismos oficiales de un determinado estado. El precio del Bitcoin se sostiene por su uso global y descentralizado, es decir, por la oferta y la demanda que exista en un determinado momento a nivel mundial.
Aquí, nos acercamos a Bitcoin desde el punto de vista de un inversionista al intentar buscar que impulsa las variaciones en el precio de un Bitcoin y en que difieren de las monedas emitidas por el Estado. Avances legales o términos con connotaciones negativas con respecto al sentimiento pueden suponer positivas respecto a la reputación, ya que, al ser un término tan novedoso y disruptivo necesita ser interpretado y analizado desde un nuevo punto de vista distinto al sentimiento.
Por supuesto, crear un modelo predictivo del Bitcoin tiene sus dificultados, ya que es un concepto novedoso (creado el año 2008) que se encuentra con los siguientes problemas:
- El sistema no está regulado. Las criptomonedas han nacido con la idea de sustituir las monedas tradicionales y, por lo tanto, legislar adecuadamente para adaptar las leyes para estas nuevas formas de pago es realmente complicado. Aparte actuaciones como las de China y Rusia que pretenden prohibir su uso [Bitcoin y ether se derrumban en los últimos días ante las amenazas de China y Rusia] no ayudan a la expansión de la moneda.
- Sus principales usuarios son muy diferentes y poco característicos. Según Google Trends, los principales usuarios de Bitcoin son programadores, personas dedicadas a actividades delictivas e inversores.
- Volatilidad Está moneda es mucho más volátil que una moneda de curso tradicional.
Como hemos comentado, esta nueva moneda no está respaldada por ninguna entidad o nación, únicamente por los usuarios que la utilizan y le otorgan un valor en cada transacción. Por ese motivo, en el caso del Bitcoin no podemos utilizar el típico análisis basado en indicadores económicos habituales, sino deberemos adaptarnos a este nuevo escenario y utilizar indicadores como la polaridad reputacional o el análisis de sentimiento para emitir estas predicciones.
Las técnicas de PLN proporcionarán un modelo que nos permitirá valorar el sentimiento o la opinión de los propios usuarios. Utilizando la información obtenida de una red social obtenida durante 5 meses se validará si existe una correlación del mercado con los resultados obtenidos de ambos modelos.
1.5. Breve descripción de los otros capítulos de la memoria
En el capítulo [3] expondremos las características de BitTweet, el dataset que hemos creado de tweets que mencionan Bitcoin anotado manualmente respecto a sentimiento y polaridad reputacional y enlazado con la cotización del Bitcoin. Para ello, se expondrá en la sección [3.2] como se han recopilado los tweets, su estructura y la información que se ha almacenado en la base de datos. En la sección [3.3] se explican los procesos para almacenar y gestionar la información económica sobre el Bitcoin. En la sección [3.3] se expondrá la plataforma utilizada para el etiquetado para acabar con la sección [3.4] donde se discutirán los resultados del etiquetado.2.Estado del Arte
Para comprobar el grado de correlación entre el precio del Bitcoin con la polaridad reputacional y del sentimiento es necesario conocer ambos términos y que algoritmos pueden ayudarnos a obtener este fin. La sección [2.1] analizarán las diferencias entre las técnicas del análisis de sentimientos y la polaridad reputacional a partir de los estudios previos publicados sobre el tema. En la sección [2.2] se analizan diferentes estudios realizados sobre la predicción del valor el valor Bitcoin a partir de redes sociales.2.1. Análisis de sentimientos vs polaridad reputacional
Como hemos comentado en la sección [1.2] , la reputación online es un reflejo del prestigio de una persona o una marca en Internet. Para poder cuantificar la reputación de una entidad, un algoritmo predictivo debe ser capaz de analizar un documento con el objetivo de encontrar la información más relevante y clasificarla acorde a sus implicaciones positivas, neutrales o negativas, es decir, debe utilizar las técnicas para el Procesamiento del Lenguaje Natural con el objetivo de poder interpretar sus implicaciones reputacionales. En este sentido, en el estudio del arte aplicado en esta sección se ha podido observar como el análisis de sentimiento es la herramienta de Procesamiento del Lenguaje Natural más utilizada para la monitorización de la reputación online. Obras como [Sentiment Analysis or Opinion Mining: A Review] [30] son un ejemplo de esta afirmación, a pesar de como se ha demostró en [European Conference on Information Retrieval] [21] que los sentimientos de un texto y sus implicaciones reputacionales para esa entidad son cosas diferentes. Realmente, la mayoría de los textos con implicaciones reputacionales son polar facts, es decir, información factual sin sentimientos explícitos. Por supuesto, medir la polaridad reputacional de un texto es más complicado cuando el documento no expresa implícitamente una reputación positiva o negativa sobre el tema analizado; pero invertir recursos en este caso puede proporcionar a las entidades aplicaciones positivas, por ejemplo, para obtener datos de opinión no estructurados sobre un servicio o producto. A pesar de que por definición la polaridad reputacional es substancialmente diferente al sentimiento de análisis, las dos tienen algunas similitudes. Es más, los trabajos sobre la polaridad reputacional han evolucionado a partir de estudios previos sobre el análisis de sentimientos, es decir, el proceso de resolver (estadísticamente) si un texto contiene sentimientos positivos, negativos o neutrales con respecto a la entidad de interés. Como ya hemos comentado, los trabajos sobre la recuperación de opinión y análisis de sentimientos se puede dividir en dos categorías: enfoques basados en léxico y en clasificación supervisada. Los enfoques basados en léxico estiman el sentimiento de un documento utilizando una lista de palabras de opinión conocida como léxicos de opinión, como por ejemplo el articulo [Proceedings of the 40th annual meeting on association for computational linguistics] [17] donde se identifica el sentimiento de un documento a través de un diccionario de palabras catalogados acorde a su sentimiento. El enfoque basado en léxico no está supervisado ya que no requiere ningún dato de entrenamiento. Enfoques más sofisticados incorporan indicadores de sentimiento adicionales como la proximidad entre términos de consulta y opinión [13] o variaciones estilísticas basadas en temas [12] . Los enfoques basados en la clasificación usan conjuntos de rasgos para construir un clasificador que pueda predecir el sentimiento de polaridad de un documento [10] . Los rasgos van desde simples n-gramas hasta características semánticas y desde características sintácticas hasta características específicas del medio [9] . Además, los enfoques basados en la clasificación pueden también dividirse en enfoques semi-supervisados y supervisados. La mayor diferencia entre las dos categorías es que los enfoques semi-supervisados combinan datos etiquetados y no etiquetados. En el artículo [Opinion Mining and Sentiment Analysis. Foundations and Trends in Information Retrieval] [8] se puede encontrar una revisión exhaustiva sobre la recuperación de opinión y el análisis de sentimientos. Mientras que en la obra [Like it or not: A survey of twitter sentiment analysis methods] [7] , encontraron una búsqueda exhaustiva centrada en el análisis de sentimientos de Twitter. A partir de los trabajos sobre los métodos de análisis de sentimientos se establecieron los primeros enfoques para el análisis de la polaridad reputacional llegando a conseguir los mejores resultados con modelos entrenados a partir de características textuales y de sentimiento. El mejor resultado fue logrado en el artículo [CEUR WORKSHOP PROCEEDINGS] [6] quienes entrenaron a un clasificador de máxima entropía utilizando el léxico de sentimientos, diagramas , número de palabras de negación y repeticiones de caracteres. [CLEF 2013 Conference and Labs of the Evaluation Forum] [5] , abordó el problema de la polaridad de reputación con un enfoque basado en la recuperación de información y encontró la clase más relevante utilizando el contenido del tweet como una consulta. [Estimating reputation polarity on microblog posts] [4] , asumió que entender cómo se percibe un tweet es un indicador importante para la estimación de polaridad reputacional de un tweet. Con tal fin, propusieron un enfoque supervisado que también consideró características de recepción como las respuestas y retweets de tweets. Los resultados mostraron que estas características fueron efectivas y que su mejor resultado se obtuvo en datos dependientes de la entidad. Nuestra contribución será investigar la técnica contextual de word embeddings en su implementación en el sistema BERT en la sección [2.1.1.] en la estimación de la polaridad reputacional de los tweets y a la predicción de valores bursátiles, comparándola con el análisis del sentimiento.2.1.1 Procesamiento del Lenguaje Natural
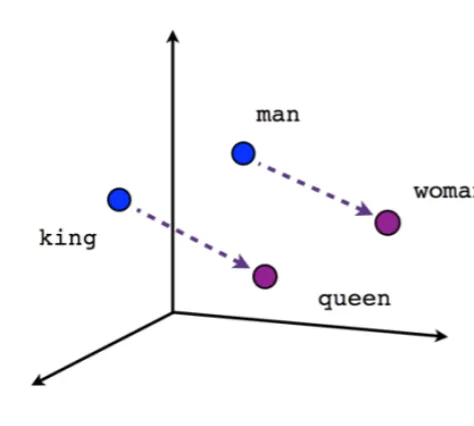
Como hemos podido comprobar en la sección [2.1] , la polaridad reputacional puede utilizar los mismos algoritmos que utilizan los analistas de datos para medir la polaridad del sentimiento. Basándonos en esa premisa, esta sección del proyecto tendrá como objetivo investigar el campo del Procesamiento del Lenguaje Natural (PLN). Como hemos analizado anteriormente, el procesamiento de textos por medio de la inteligencia artificial supone un reto al momento de presentar un texto determinado en un algoritmo y que este lo entienda en su totalidad, preservando las características del lenguaje. El procesamiento del lenguaje natural moderno (a partir de 2013) utiliza con frecuencia la técnica de los embeddings, representaciones de palabras en un vector n-dimensional, partiendo de la premisa de que su cercanía espacial conlleva alguna clase de relación entre los mismos. En las figuras [1] [2] [3] se pueden analizar 3 ejemplos gráficos de este algoritmo.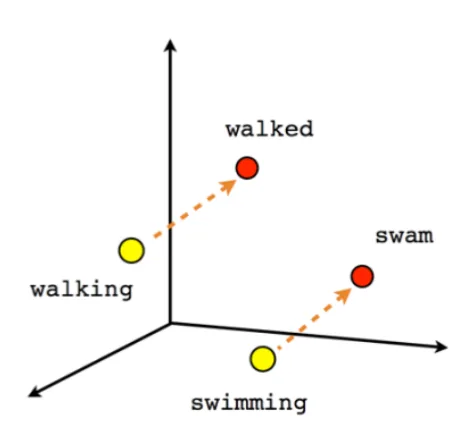
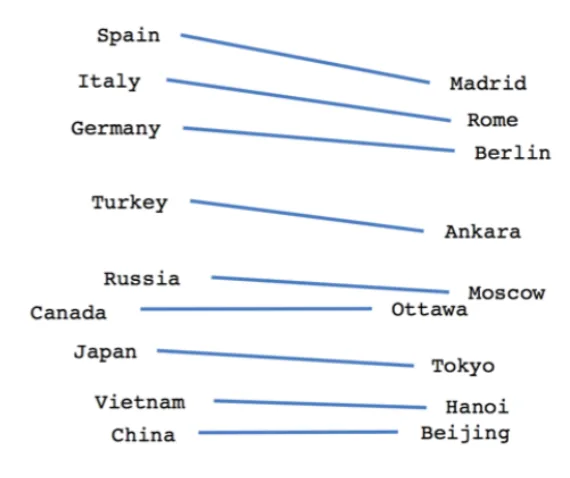
Proximidad de localización
Como se puede comprobar, el primer paso de este algoritmo es asignar a cada palabra un vector de números a partir de su contenido semántico (cabe recordar que las redes neuronales son más eficientes con números). Si se analiza la imagen [1] , se observa un ejemplo semántico de cómo se representarían cuatro palabras diferentes pero relacionas en un espacio vectorial. Si se realiza una operación matemática como: Rey menos hombre más mujer se obtendrá como resultado un vector muy cercano al que se ha representado Reina. Esta evolución permite utilizar sistemas de redes neuronales para comprender la semántica de las palabras, aunque sin llegar a comprender las relaciones entre las mismas. Para resolver esta carencia, las técnicas del NLP han mejorado lo suficiente hasta llegar a generar lo que hoy conocemos como `modelos de lenguaje'. Los modelos de lenguaje son patrones de Machine Learning destinados a predecir cuál ha de ser la siguiente palabra de un texto en función de todas las palabras anteriores. El gran potencial de esta técnica es que, una vez que la IA comprende la estructura de un lenguaje, es relativamente fácil descargar estos modelos preentrenados y adaptarlos mediante `fine-tuning' a otras tareas diferentes a la creación de textos, como puede ser la clasificación de textos. Dentro de todos los sistemas publicados hasta el momento y después de realizar una búsqueda entre diferentes soluciones, en esta investigación nos hemos decantado por BERT, uno de los modelos más avanzados para la representación de palabras y textos. BERT es un sistema que proporciona contextual word embeddings, es decir, cada palabra recibe una representación dependiente del contexto en el que aparece. Los contextual word embeddings son sistemas preentrenados que proporcionan una riqueza semántica sin precedentes, y que están cambiando el PLN desde el año 2018. Aunque hay varios sistemas que compiten con BERT en la actualidad, el hecho de que BERT sea de código abierto y bien documentado hace que sea la opción más popular y la que hemos adoptado en este trabajo.Bert
Como se ha podido comprobar a través del contenido de esta sección, para poder clasificar la polaridad reputacional de un texto será necesario tanto el análisis del documento mediante espacio de vectores como el análisis del contexto en el que ocurren las palabras. Las consecuencias de esta nueva interpretación las podemos ver reflejadas en la palabra rey del ejemplo anterior, ya que poseerá un significado diferente dependiendo del contexto en el que se use la palabra. Esta sutileza es necesaria, ya que capturar el sentido gramático de las palabras puede aportar información relevante sobre su polaridad. Por ejemplo, no es lo mismo utilizar una palabra como objeto o como sujeto en una oración, con un sentido o con otr En este sentido, las técnicas de procesamiento de lenguaje natural (PLN) basadas en algoritmos de inteligencia artificial (IA) nos ofrecerá una mejor solución que los algoritmos analizados hasta ahora. Para ello se puede utilizar la experiencia previa de este campo en la traducción de idiomas, análisis de sentimientos o búsqueda semántica que ofrecerá una ayuda a la hora de escoger el mejor camino para nuestra tarea. Otro beneficio de obtener la experiencia previa en otras tareas es la capacidad de optimizar más eficientemente el modelo creado. Estos algoritmos necesitan alimentarse de diversos conjuntos de datos lo suficientemente grandes como para entrenar los modelos que utilizan. Los algoritmos de aprendizaje profundo imitan el comportamiento de las neuronas en el cerebro humano, es decir, a medida que aumenta el conjunto de entrenamiento mejoran sus resultados y, por lo tanto, cualquier conjunto ya etiquetado nos puede ayudar a obtener mejores resultados en el proyecto. Ahora bien, debido a que el PLN es un campo con muchas tareas distintas, la mayoría de los conjuntos de datos específicos de tareas contienen solo unos pocos miles o unos cientos de miles de ejemplos de documentos etiquetados por el hombre. Para ayudar a cerrar esta brecha en los datos, los investigadores han desarrollado una variedad de técnicas para entrenar modelos de representación de lenguaje de propósito general utilizando la enorme cantidad de texto no anotado en la web (conocido como pre-entrenamiento). El modelo pre-entrenado puede luego ajustarse a tareas de PLN de datos pequeños como la respuesta a preguntas y el análisis de sentimientos, lo que resulta en mejoras sustanciales de precisión en comparación con la capacitación en estos conjuntos de datos desde cero. Y en este contexto, el 2 de noviembre del 2018 Google presentaba Open Sourcing BERT (Bidirectional Encoder Representations from Transformers), el primer modelo contextual profundamente bidireccional, representación de lenguaje sin supervisión, pre-entrenado usando solo un corpus de texto plano. BERT se basa en el trabajo reciente en representaciones contextuales previas al entrenamiento, que incluye el Aprendizaje de Secuencia Semi-supervisado, el Pre-Entrenamiento Generativo, ELMo y ULMFit. Sin embargo, a diferencia de estos modelos anteriores, BERT es la primera representación de lenguaje no supervisada, profundamente bidireccional, pre-entrenada usando solo un corpus de texto simple. Según lo explicado por Jacob Devlin y Ming-Wei Chang, investigadores de Google AI, BERT es único porque es bidireccional y permite el acceso al contexto desde direcciones pasadas y futuras y desatendido, lo que significa que los datos se pueden capturar sin clasificar ni marcar. Esto contrasta con los modelos tradicionales de PLN que producen una incrustación de palabras sin contexto (una representación matemática de una palabra) para cada palabra en su vocabulario. Las representaciones pre-entrenadas pueden ser libres de contexto o contextuales, y las representaciones contextuales pueden ser unidireccionales o bidireccionales. Los modelos sin contexto comentados anteriormente generan una representación de incrustación de una sola palabra para cada palabra en el vocabulario. Por ejemplo, la palabra "banco'' tendría la misma representación libre de contexto en "cuenta bancaria'' y "banco del río''. En su lugar, los modelos contextuales generan una representación de cada palabra que se basa en las otras palabras de la oración. Por ejemplo, en la oración "Accedí a la cuenta bancaria'', un modelo contextual unidireccional representaría "banco'' basado en "Accedí a la'' pero no a "cuenta''. Sin embargo, BERT representa "banco'' utilizando su contexto anterior y el siguiente. "Accedí a la [...] cuenta'', comenzando desde el fondo de una red neuronal profunda, haciéndola profundamente bidireccional. A continuación, se muestra una visualización de la arquitectura de la red neuronal de BERT en comparación con los métodos de entrenamiento previo contextual más avanzados. Las flechas indican el flujo de información de una capa a la siguiente. Los cuadros verdes en la parte superior indican la representación contextualizada final de cada palabra de entrada: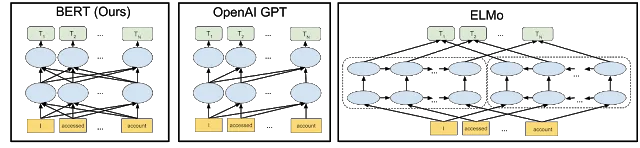
2.2. Predicción del valor Bitcoin a partir de redes sociales
En los mercados de divisas tradicionales es común ver a los inversores utilizar alguno de los siguientes enfoques (en conjunto o por separado) para predecir las tendencias del mercado:- Análisis fundamental: la técnica que utiliza los factores subyacentes de un valor para estimar su valor. En relación con las monedas emitidas por el Estado, esta técnica se centra en indicadores como las previsiones de crecimiento de una nación, los niveles de importación y exportación, el turismo, las medidas políticas, los niveles de deuda, el PIB y las relaciones internacionales. Éstos se utilizan como parámetros para un modelo de valoración. Si se considera que la moneda está por debajo del precio, entonces tiene sentido comprar esa moneda, de lo contrario para vender. El artículo Madan et al. [28] es un ejemplo de este enfoque. En él se observó que la investigación existente no consideraba la relación entre otros factores en el espacio de características y la estimación de precios de Bitcoin cuando se aplicaba a un agente comercial. Al analizar 16 características independientes, crearon un algoritmo de aprendizaje automático para predecir el precio de Bitcoin. Estas 16 características están relacionadas con el precio de Bitcoin y se registraron diariamente durante los últimos 5 años. Su estudio también consideró el uso de precios de Bitcoin sólo como un medio de predecir la dirección de los futuros cambios de precios.
- Análisis técnico: es un método alternativo de asignación de valor a una acción que analiza la actividad del mercado analizando datos tales como precios históricos y volumen diario negociado. Este enfoque no intenta medir el valor intrínseco de una seguridad, sino que utiliza modelos matemáticos y análisis estadístico para identificar patrones con el fin de predecir la actividad futura. Un ejemplo de este análisis ese el articulo [Bitcoin Trading Agents] [22] donde se propone predecir el precio del Bitcoin a través de una regresión bayesiana. En el documento se dan n puntos de datos etiquetados ( , ) para 1 . Estos datos de entrenamiento (precios históricos de Bitcoin) se utilizan para predecir la etiqueta desconocida (futuro precio de Bitcoin) dada una x determinada. Es decir, el modelo utilizado se centra en la comprensión de la información que se encuentra en los datos históricos relacionados co
- Blockcain.info donde se ha obtenido toda la información relacionada con estadísticas monetarias, actividad de la red, detalles sobre los bloques, tasas de creación de nuevas monedas y transacciones. Por supuesto, está incluida el valor de intercambio USD a bitcoin y viceversa junto con su volumen.
- Gooogle Trends. Esta plataforma es una herramienta de Google Labs que muestra los términos de búsqueda más populares del pasado reciente. Utilizando la palabra Bitcoin como consulta, se han obtenidos los principales temas relacionados con la criptomoneda.
- Datos macroeconómicos. Los datos macroeconómicos de S&P500, Chicago Board Options Exchange y Volatility Index.
3.BitTweet dataset
En este capítulo se especificará el dataset escogido, cómo se ha obtenido, etiquetado y gestionado para posteriormente ser utilizado en la fase de experimentación. Para ello dividiremos este capítulo en diferentes secciones. En la sección [3.1] se analizará cómo se ha obtenido la información, las fuentes utilizadas y cómo se han gestionado. En la sección [3.2] se expondrá cómo se ha realizado el proceso de clasificación, las normas de etiquetado aplicadas para cada una de las diferentes categorías y dónde se han almacenado. Por último, en la sección [3.3] se expondrá cómo se ha llevado a cabo el proceso de etiquetado, y en la sección [3.4] se resumirán los resultados.3.1. Fuentes de información
En esta sección vamos a especificar las dos fuentes de información utilizadas en el proyecto: por una parte, la red social Twitter, de donde obtendremos los comentarios escritos por los usuarios, y por otra la web www.blockchain.com de donde se registra la información económica sobre el Bitcoin. En la sección [3.1.1] se expondrá qué es Twitter, por qué hemos escogido esta red social, cómo hemos captado la información de la aplicación y dónde la hemos almacenado, para continuar en la sección [3.1.2] contextualizando el Bitcoin, qué tipo de información podemos obtener y como la gestionamos.3.1.1 Twitter
Client/StreamingClient, ventana de consulta, limites de cuota o coste, estrategia de hidratacion de IDs, tratamiento de posts borrados/protegidos y base etica para recolectar datos sociales.
- ID_rubenPrimaria: Número entero que identifica el registro.
- created_at: Fri Nov 02 17:18:31 +0000 2018Fecha de creación del tweet
- id: 1058408022936977409. Número entero que identifica el tweet.
- text: RT @harmophone: "The innovative crowdsourcing that the Tagboard, Twitter and TEGNA collaboration enables is surfacing locally relevant conv…,Campo de texto donde se almacena el contenido del tweet:
- sia_sentimiento: Positive Acrónimo de Sentiment Intensity Analyzer. Valoración del sentimiento por parte de VADER, librería para análisis del sentimiento comentada en la sección [1.2] .
- textblo_sentimiento: Positive Valoración del sentimiento por parte de Vader, librería para análisis del sentimiento comentada en la sección [1.2] .
- textotraducido: @harmophone:"El innovador crowdsourcing que permite la colaboración Tagboard, Twitter y TEGNA está surgiendo a nivel local. . . '', Campo de texto donde se almacena el tweet traducido por google translate. Por ejemplo:
- Información extraída de Twitter no utilizada para el proyecto como:
- source:Twitter Web Client.
- truncated: false.
- in_reply_to_status_id: null.
- in_reply_to_user_id: null.
- in_reply_to_screen_name: null.
- geo:null.
- coordinates: null.
- place: null.
- contributors: null.
- retweeted: false.
- lang: en.
3.1.2 Bitcoin y Blockchain
Como hemos comentado previamente, Bitcoin es un sistema de moneda digital peer-to-peer programado en código abierto [24] y considerado como una alternativa potencial a las monedas estándar. Utiliza un protocolo criptográfico para controlar la creación y transferencia de dinero, asegurando que conserva su valor e impidiendo ser doblemente gastado. Se crea y se transfiere sin la necesidad de una autoridad central de gobierno, utilizando recursos computacionales al alcance de cualquier usuario y transfiriéndose directamente de una cuenta a otra utilizando algoritmos criptográficos. Al igual que el resto de los mercados de divisas, en Bitcoin existe una zona de intercambio abierto que permite a los consumidores e inversores comprar y vender bitcoins. El precio al que se negocia el Bitcoin está relacionado con el valor percibido por el inversor, ya que no le afectan los factores como la cantidad de productos importados y exportados o el respaldo de los organismos oficiales de un determinado estado. Debido a esta característica, el precio del bitcoin se sostiene por su uso global y descentralizado, es decir, por la oferta y la demanda que exista en un determinado momento a nivel mundial. En este contexto, el año 2011 se lanzó Blockchain.info, un servicio capaz de proporcionar a sus usuarios datos sobre cantidad de transacciones, bloques minados de Bitcoin, gráficos, estadísticas y recursos para desarrolladores con el objetivo de ayudar a los usuarios de la criptomoneda a crear una estrategia comercial eficaz. Tal y como se expone en la sección [2.2] este sitio web dispone de una API que nos proporcionará las principales estadísticas monetarias, actividad de la red, detalles sobre los bloques, tasas de creación de nuevas monedas y valor de la última transacción. Este último dato se utilizará en el proyecto para analizar la correlación del precio del Bitcoin con el sentimiento y la polaridad reputación. En la dirección GitHub expuesta a continuación ( https://github.com/al118345/java_client_blockchain/blob/master/client_java_blockchain.java ), se puede consultar el código implementado donde se obtienen los siguientes datos:- transaccionessinconfirmar: Número de transacciones pendientes no confirmadas.
- precio24horasUSD: Precio ponderado del Bitcoin durante las últimas 24 horas.
- marketcap: Capitalización total del mercado.
- 24hrtransctioncount: Cantidad de transacciones realizadas las últimas 24 horas.
- 24numeroBitcoinsent: Cantidad de Bitcoin intercambiados las últimas 24 horas.
- hashreat: Tasa estimada de hash de red en gigahash
- dificultad: Dificultad actual de la red Bitcoin.
- longitudbloque: Longitud del último bloque minado.
- totalbitcoin: Número total de Bitcoin en circulación.
- fecha: Fecha de creación del registro.
3.2. Recolección
En esta sección se expondrán como se ha realizado el proceso de clasificación, las normas de etiquetado aplicadas para cada una de las diferentes categorías. Primero de todo, es necesario recordar que en el proyecto se gestionarán dos tipos de etiquetados diferentes, que serán los etiquetados para:- La Polaridad Reputacional
- El Análisis del Sentimiento.
3.2.1 Polaridad Reputacional
Como descubrimos en la sección [2.1] , es más importante como afecta un tweet a la reputación de la moneda que el sentimiento que posee el mismo. Teniendo en cuenta esta afirmación, las reglas de anotación utilizadas para la recolección de tweets respecto a la polaridad reputacional han sido las siguientes:- Positivo: Se considerará positivo todo aquel tweet que:
- Valore el Bitcoin como un sistema estable y seguro de inversión.
- Una moneda de uso real.
- Una predicción positiva sobre la evolución de su precio
- Explique un avance tecnológico
- De ejemplos de uso.
- Neutrales: Se considerará neutral todo aquel tweet que:
- No aporte ningún información nueva o útil
- Información sobre el precio actual del Bitcoin
- Publicidad
- Consejos
- Negativos: Se considerará negativo todo aquel tweet que:
- No valore al Bitcoin como un sistema estable y seguro de inversión.
- Critique el uso del Bitcoin.
- Hable sobre problemas relacionados con su uso.
- Asocie al Bitcoin ha hechos delictivos.
- Todos aquellos que contenga la palabra Drop Gold, aunque olvidarse del oro puede tener una connotación negativa respecto al sentimiento, desde el punto reputacional es positivo. Dentro de la criptomoneda existe un movimiento a favor de sustituir el oro por Bitcoin.
- ETF son positivos, ya que es la forma ágil de invertir, sin tanto riesgo y a un coste mejor que un fondo de inversión. Un ETF, o fondo de inversión cotizado, del Bitcoin supone un avance muy importante para la criptomoneda ya que permitiría la entrada a más inversores. Un ejemplo podría ser:
- Predicciones de precio positivas para el Bitcoin. Por ejemplo, todo aquel tweet que contenga un +5% de aumento en la última hora, o un aumento con respecto al actual precio se debe considerar positivo.
- Utilizar Bitcoin como sinónimo de seguridad:
- Los avances tecnológicos o legales también se consideran como un aspecto positivo ya que, a pesar de tener un sentimiento neutral supone una repercusión positiva en su reputación. Por ejemplo:
- Adopción por parte de grandes empresas.
- Críticas a los que no utilizan el Bitcoin como moneda. Realmente son negativos de sentimiento, ya que posee un sentimiento de crítica, pero son positivo para la reputación. Por ejemplo:
- Concursos. Se consideran positivos porque aparte de intentar dar a conocer la moneda, reconoce su valor al ser objeto de deseo por parte de los participantes. También le otorga utilidad de la moneda e interés por ella. Ejemplo:
- Se consideran positivos aquellos tweets con aspectos positivos sobre su funcionamiento o afirmaciones positivas sobre la moneda:
- El Bitcoin asociado como solución a los colapsos financieros. En ese sentido, a pesar de tener un sentimiento negativo debido a la palabra colapso, decir "no seas uno...'' da entre ver el sentimiento positivo en la polaridad como solución a un problema.
Hey, check this out: [New Bitcoin ETF (BTC) and Ethereum (ETH) submitted to the SEC] (through the Quarry app) https://t.co/Ie5q6Y9QWO
$11,500 #bitcoin Price Will Absolutely Become a Reality in 2019 ( https://t.co/uQB3ttUSid ) https://t.co/n5xFOm17m3
Lot’s of green today for crypto!! #bitcoin #bitcoinrich ( https://t.co/SWEM4EjblH )
@brendan_dharma Well it happened on bitcoin and therefore would not be a scam
New #Blockchain Service Builds Worldwide Standardized Verification System For Certificates @newsbtc - https://t.co/3qBnN86cf6 #bitcoin #cryptocurrency #ethereum #crypto #tech #btc #blockchaintechnology #fintech #ecosystem #ICO #Ethereum #IoT #AI #BigData #altcoin #ETH https://t.co/eyorvyvJ7c
OCF aims to transform philanthropy to detect the world's first decentralized charitable foundation to build a future in which blockchain technology can avoid ending all forms of poverty and inequality.#ooobtc #obx #crypto #bitcoin #ethereum #blockchain #btc #toqqn
Facebook rolls back ban on cryptocurrency ads as it ramps up its own blockchain efforts #cryptocurrency #btc #bitcoin ( https://t.co/MAIqyT1XbJ )
RT @crypto__mak: NYSE Arca Wants to List Bitcoin and T-Bill-Backed Fund ( https://t.co/MQXHCXArKv ) #News #bitcoin #nysearca
Google: NoCoiner ... I would post it here, but Twatter only lets me write not enough words ;)
RT traía un CONCURSO MEGA a Freebitcoin Síguenos en Instagram para obtener actualizaciones bitcoin freebitcoin crypto crypto
RT @CryptoBac: #btc crypto #cryptocurrency Everything is going great here!
RT @ArminVanBitcoin: Accumulate #Bitcoin today. Survive the big financial collapse tomorrow. None of my friends are listening. Don't be one
- Aquel tweet que contenga preguntas básicas o sin contenido referentes al Bitcoin como ¿conocéis bitcoin? ¿Habéis oído hablar del bitcoin? que no aporta ninguna información sobre la polaridad reputacional.
- Tweets cortos con información poco o nada útil como:
- Información económica sobre el Bitcoin. Un ejemplo pueden ser datos sobre precio actual del Bitcoin o la capitalización global respecto al dolar como se muestra a continuación:
- Eventos sobre temas de blockchain o Bitcoin que no aporten ningún beneficio.
- Publicidad sobre plataformas de intercambio de criptomonedas, como, por ejemplo:
- Grupos de telegram sobre el Bitcoin.
- Guías para conocer más el Bitcoin, consejos sobre cómo utilizarlo o información sin ningún sentimiento reputacional.
RT @azbit_news:
Dolar Bitcoin
@ #1, Bitcoin with unit price of $5,926.35, market cap of $104,823,794,536 (56.12%), and 24 hr vol. of $17,981,007,232.3 (31.74%)
Don't forget the Tampa Bay #Bitcoin meetup tomorrow. RSVP while you still can: https://t.co/wSff9z2lPz
https://t.co/J8amkmiqmE The most popular cryptocurrency exchange #cryptoexchange #blockchain
RT @authpaper: Don't forget to also join our #telegram group to earn more #bounty rewards! Telegram link: https://t.co/xi6hNWnFGy #AUPC #A
RT @MervikHaums: Yes! You own your funds only if you own your keys. #binance #bnb #hacked #bitcoin #btc #toqqn #tqn #crypto #exchange http
Blockchain: Bitcoin, Ethereum, Cryptocurrency: The Insiders Guide to Blockchain Technology, Bitcoin Mining, Investing and Trading Cryptocurrencies (Blockchain business, & Blockchain for Dummies) https://t.co/2Y7EDhqFIb #blockchain #ad
- Tweets acerca de Craig Wright como creador del bitcoin o positivos hacia esa persona se consideran negativos. Este nombre tiene una reputación negativa en el Bitcoin y, por lo tanto, todo lo relacionado con él tendrá una connotación negativa.
- Comparaciones despectivas con el Bitcoin.
- Los referidos a la falta de legislación o problemas legales.
- Todos aquellos tweets que informen o analicen Hackeos
- Todos los tweets donde se asocie el bitcoin a pagos no legales.
- Aquellos que se habla de términos económicos negativos como por ejemplo bajadas de precio o posibles correcciones del Bitcoin.
Satoshi Files: Calvin Ayre Teases 'More Evidence' Craig Wright Created Bitcoin https://t.co/wYkBf416o9
@JamesTodaroMD @TusharJain_ Bitcoin will never be free state money! But Ethereum will! Negativo corregir
Hackers Steal $40.7 Million in #Bitcoin From Crypto Exchange Binance https://t.co/rMAQVRsKLN
https://t.co/Qc5JBeuw4B @LukeDashjr at 36:30 Cz from Binance said some community members and core bitcoin devs offered a roll back as a tech solution? what core member offered this? would interesting to know
Are you paying for this media coverage in bitcoin or rubles Nigel Farage? You' ve been investigated for funding irregularities before - you will be again. #youwontgetawaywithitforever #charlaton #TuesdayTruths #sideofabuslies
Is #bitcoin Due for a Correction? for BITMEX:XBTUSD by oh92 #XBTUSD https://t.co/Rgkbt2wpAO https://t.co/pcjJ8j8E5p
RT @CredibleCrypto: There are ALWAYS pullbacks, so stop fomo-ing if you miss a leg up and prep your plan to buy the next correction. https:…
3.2.2 Valoración del sentimiento
En esta sección aplicaremos el mismo etiquetado que analizamos en la sección anterior, pero desde la perspectiva del sentimiento. Para ello, es necesario analizar el contenido del propio tweet con el objetivo de etiquetarlo como positivo, negativo o neutro respecto al sentimiento expresado respecto el Bitcoin.- Positivo: Se considerará positivo todo aquel tweet que:
- Valore el Bitcoin como algo positivo.
- Contenga palabras positivas
- Aumentos de precio
- Publicidad
- Comparaciones positivas.
- Neutrales: Se considerará neutral todo aquel tweet que:
- Tutoriales
- Información económica sobre el Bitcoin
- Ejemplo de uso
- Negativos: Se considerará negativo todo aquel tweet que:
- Se escriba sobre ataques cibernéticos.
- Se escriba sobre problemas relacionados con su uso.
- Asocie al Bitcoin a hechos delictivos.
- Muestre desprecio hacia el Bitcoin.
- El contenido del tweet tiene palabras positivas como:
- Se define el Bitcoin como algo real y no como una estafa
- Tweets donde se presenta a la criptomoneda como solución a problemas:
- Comparación positiva del Bitcoin sobre otra Criptomoneda.
- Publicidad positiva sobre el Bitcoin.
- Tweets sobre el aumento del precio del Bitcoin.
- Todos aquellos tweets donde a pesar de poseer términos negativos, la forma de utilizarlo y el contexto de las palabras lo transforman en positivos.
( https://t.co/J8amkmiqmE )The most popular cryptocurrency exchange#cryptoexchange #blockchain
Bitcoin, Ethereum, Ripple and IOTA Are The Most Important Projects among 1500+ Cryptocurrencies, KPMG Report( https://t.co/ZDhJDnnoml )#Bitcoin#BitcoinLifestyle ( https://t.co/uQEFmPmwGb )
@brendan_dharma Well it happened on bitcoin and therefore would not be a scam
ByzCoin has the potential to overcome the lag through scalable collective signing, committing #Bitcoin transactions irreversibly within seconds. Watch @brynosaurus present an outline and how it can be a solution to Bitcoin scalability ( https://t.co/GBfd7iN0bA ) #blockchain ( https://t.co/GBfd7iN0bA ( https://t.co/GBfd7iN0bA ) #blockchain )
@brucefenton The problem is that Litecoin is worse than Bitcoin on all point. And that what Litecoin do mostly is copying Bitcoin.Betting on a different coin than Bitcoin is fine. But so far no coin has been better.
RT @ProofOfSteve: Every time we open and close above one of these trend lines we go straight up. Guess what, this is the 4th time in BTC history this has happened. #BTC #bitcoin #crypto #hodl $btc $bitcoin ( https://t.co/8bdQ0I0Mtd )
Bitcoin Soars Above $7,000 As Crypto Comeback Continues ( https://t.co/KQ7U0bRwjR ) #Money #Finance #Economics #Market
Bitcoin whales are smart money. Do not be stupid money ( https://t.co/bDXT5tOaK2 )
- Todos aquellos donde se presentan una guía de información, un tutorial o cualquier tipo de ayuda técnica a los usuarios como, por ejemplo:
- Técnicos de bolsa sin ningún tipo de sentimiento como:
- Tweets con información sobre el uso del Bitcoin donde no se exprese ningún sentimeinto.
- Tweets sobre libros sobre el Bitcoin.
Blockchain: Bitcoin, Ethereum, Cryptocurrency: The Insider’s Guide to Blockchain Technology, Bitcoin Mining, Investing and Trading Cryptocurrencies (Blockchain business, & Blockchain for Dummies) ( https://t.co/2Y7EDhqFIb ) #blockchain #ad
Bitcoin 55k target came just short Good example of why OBV has been more important lately than RSI Bear div started on RSI but not OBV Once OBV showed div is when it dropped Top Goon X signaled the dead cat bounce and just gave same signal on 12H 4648k area to watch
@ #1, Bitcoin with unit price of $5,926.35, market cap of $104,823,794,536 (56.12%), and 24 hr vol. of $17,981,007,232.3 (31.74%)
#ETH Buy at #Paribu and sell at #Gate.io. Ratio: 0.92% Buy at #Koinim and sell at #Bitfinex. Ratio: 4.76% Buy at #BtcTurk and sell at #Bittrex. Ratio: 1.04% Buy at #BtcTurk and sell at #Bitfinex. Ratio: 6.06% #bitcoin #arbitrage #arbitraj #arbingtool https://t.co/xiFUPzcOcC
University Students Choose One Dollar Over One Bitcoin @bitcoinist #Bitcoin #Bitcoin Acceptance #Bitcoin Education #Bitcoin Price #bitcoin #dollar #students ( https://t.co/Gs06qUFBEd )
Descargar EPUB Mastering Bitcoin: Programming the Open Blockchain https://t.co/3nXIw3Eerh
- Tweets donde aparecen palabras negativas como "colapso'', "no están'' escuchando:
- Todos aquellos que contenga la palabra Drop Gold, ya que desprenderse del oro tiene una connotación negativa respecto al sentimiento.
- Tweets redactados con palabras que poseen un significado negativo respecto al valor del Bitcoin, como por ejemplo la palabra "corrección'' o "disminución''.
- Tweets sobre ataques cibernéticos, bots o problemas técnicos
- Tweet sobre acciones de dudosa legalidad o connotación negativa.
- Comparaciones despectivas del Bitcoin
RT @ArminVanBitcoin: Accumulate #Bitcoin today. Survive the big financial collapse tomorrow. None of my friends are listening. Don't be one
¿Does Grayscale’s Latest ##DropGold for #Crypto Effort Entirely Miss the Point? ( https://t.co/TD7U54ENzi ) #bitcoin
Is #bitcoin Due for a Correction? for BITMEX:XBTUSD by oh92 #XBTUSD https://t.co/Rgkbt2wpAO ( https://t.co/pcjJ8j8E5p )
Bitcoin (BTC) Price Weekly Forecast: Technical Bias Signaling Fresh Increase ( https://t.co/qwgbNrkgY1 ) #Bitcoin #Cryptocurrency #Analysis #BTC #Technical"@brucefenton The problem is that Litecoin is worse than Bitcoin on all point. And that what Litecoin do mostly is copying Bitcoin.
Hackers Steal $40.7 Million in #Bitcoin From Crypto Exchange Binance ( https://t.co/rMAQVRsKLN )
Homeland Security Warns Bots Are Exploiting Decentralized Crypto Exchanges#bitcoin #ripple #altcoin #cryptocurrencymarket #SmartCash #cryptonews #coldwallet #er20( https://t.co/xcQh00U6zw )
@binance quit holding our funds hostage. If we wanted our money to have delays wed use fiat. Your damage has been assessed already so there s no reason for this continuation. Binance BinanceHack btc bitcoin
Are you paying for this media coverage in bitcoin or rubles Nigel Farage? You’ve been investigated for funding irregularities before - you will be again. #youwontgetawaywithitforever #charlaton #TuesdayTruths #sideofabuslies
@JamesTodaroMD @TusharJain_ Bitcoin will never be free state money! But Ethereum will!
@cryptochrisw #securypto product absolutely matter.. Without product it has no function at all! And become waste! #cryptocurrency #bitcoin #altcoinVicious Crypto Crash Could Supercharge Bitcoin Price Rally to $20,000 ( https://t.co/DzuD0HCYgv )
3.3. Proceso de etiquetado
El objetivo de esta sección ha sido analizar qué tipo de interfaz e infraestructura era la más adecuada para el etiquetador, es decir, el programa encargado de recopilar, mostrar y almacenar la valoración de un tweet desde el punto de vista de la polaridad reputacional y el sentimiento. Al ser una tarea larga, repetitiva y con múltiples opciones es muy fácil cometer errores durante el proceso de etiquetado. Para intentar evitar fallos se ha optado por utilizar la web mostrada en la figura ( [3.1] . En ella se implementó una interfaz amigable para el etiquetador, intentando optimizar su esfuerzo utilizando múltiples colores, filas y un diseño responsive basado en Bootstrap otorgando al etiquetador total independencia para escoger el dispositivo que se adapte mejor a su forma de trabajar. Respecto a la interfaz, en la primera parte de la interfaz tendremos el etiquetado de la Polaridad reputacional. La fila está dividida en botones y cada botón tiene un color diferente dependiendo de su finalidad, es decir, dependiendo de su polaridad reputacional: Positiva, Neutral, Negativa y Dudosa. La segunda parte del formulario corresponde al etiquetado del sentimiento. En esta línea el usuario selecciona una etiqueta que simboliza su percepción con respecto al sentimiento del tweet entre los diferentes checkbox disponibles. Es complementario a la línea superior, y únicamente puede ser seleccionado un único checkbox. Por último, polaridad dudosa, se utiliza para almacenar aquellos tweets que tengamos dudas sobre su temática del Bitcoin. De esta forma, se diferencian del resto, con el objetivo de analizarlo individualmente con posterioridad. Siguiendo un principio de sencillez, la web ha sido implementada para poder ser visualizada desde cualquier dispositivo, tanto móviles como ordenadores, con el objetivo de permitir al usuario etiquetar de forma independiente del dispositivo usado. Aparte, el funcionamiento es muy sencillo, simplemente al hacer click en un botón se almacena la información asociada del botón y el checkbox seleccionado. Para facilitar el proceso de creación del dataset se ha implementado un seleccionador dinámico de tweets, es decir, cada vez que se recarga la web selecciona aleatoriamente el tweet a analizar con el objetivo de crear un conjunto de entrenamiento lo más real y esparcido en el tiempo posible con el objetivo de etiquetar tweets con diferentes noticias, asunto u opiniones. También se le proporciona información como la fecha de creación, cantidad de transacciones, precio, etc. para ayudar al etiquetador a llevar a cabo su tarea. La dirección para consultar la información es ( http://test.1938.com.es/web_pruebas_v2.php )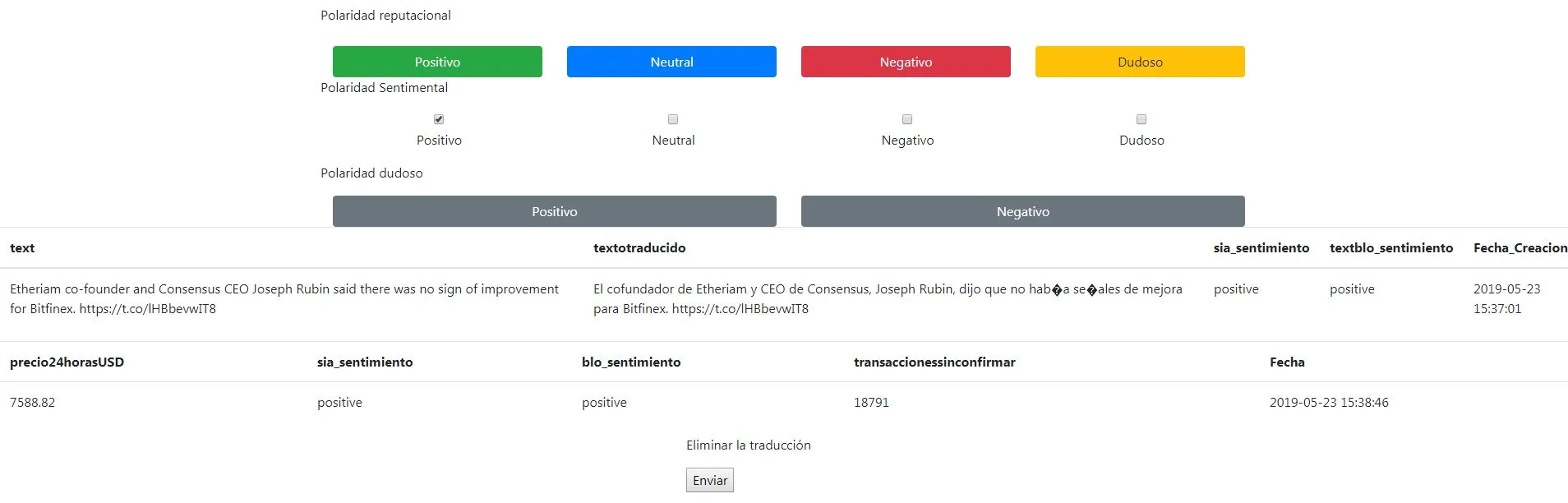
3.4. Discusión
Nuestras anotaciones manuales sobre la colección TweetCoin son, hasta donde sabemos, el primer dataset manual en el que se puede cuantificar la diferencia entre sentimiento y polaridad reputacional; en el dataset de referencia RepLab se anota la polaridad reputacional, pero no el sentimiento; y en la mayoría del resto de datasets se anota sólo el sentimiento. En la figura [3.2] se recoge la matriz de confusión entre ambos. Se puede apreciar que, en un 37% de los casos (600 tweets sobre un total de 1145), las anotaciones no son coincidentes. Las discrepancias más frecuentes son, por este orden: (1) sentimiento positivo con polaridad reputacional neutral; (2) sentimiento neutral con polaridad reputacional positiva; (3) sentimiento negativo con polaridad reputacional positiva.Esto confirma la intuición de que cuando estudiamos la Polaridad Reputacional y Análisis del Sentimiento estudiamos dos formas diferentes de medir la reputación online de una marca.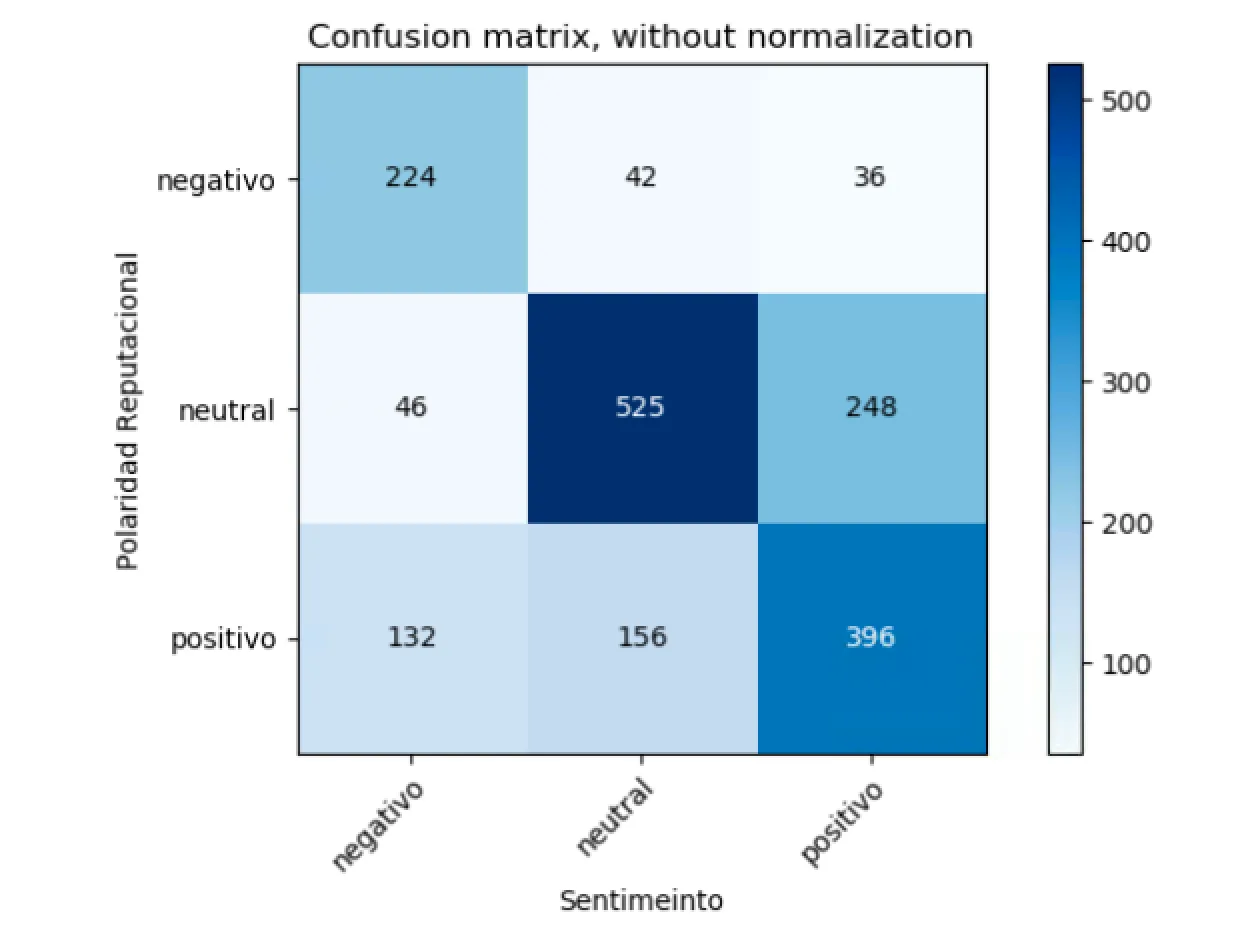
New #Blockchain Service Builds Worldwide Standardized Verification System For Certificates @newsbtc - https://t.co/3qBnN86cf6 #bitcoin #cryptocurrency #ethereum #crypto #tech #btc #blockchaintechnology #fintech #ecosystem #ICO #Ethereum #IoT #AI #BigData #altcoin #ETH https://t.co/eyorvyvJ7c
Otro ejemplo, con polaridad reputacional positiva y con sentimiento negativo puede ser críticas a las personas que no utilizan Bitcoin como el siguiente tweet:Google: NoCoiner ... I would post it here, but Twatter only lets me write not enough words ;)
Como podemos ver en la matriz, durante el periodo de recolección nos hemos encontrado con una gran cantidad de este tipo de tweets. Exactamente hemos localizado 168 tweets donde el sentimiento y la polaridad reputacional son opuestos. También hemos detectado una gran cantidad de tweets positivos respecto al sentimiento y neutrales a la polaridad reputacional como por ejemplo publicidad:Find the Largest Telegram group provide Free Crypto BOT; Crypto Signal Bitcoin forum - Discuss and Learn About Cryptocurrency
4.Diseño experimental
Lista de reproducibilidad
Conserva juntos la partición cronológica, preprocesamiento, etiquetas, semillas, versiones y fuente del precio de Bitcoin. Una partición aleatoria puede filtrar lenguaje futuro al entrenamiento y exagerar la capacidad predictiva.
4.1. Sistema de Análisis del sentimiento con VADER
Esta sección tiene como finalidad encontrar un algoritmo o modelo que podamos utilizar como baseline. Lo que se busca es un sistema implementado como una librería en Python que evite el coste de realizar un proceso de etiquetado manual, se pueda integrar al proceso de recopilación de los tweets y este validado por diferentes estudios. Entre las diferentes posibilidades que existen, para este proyecto se ha utilizado VADER (Valence Aware Dictionary and sEntiment Reasoner) ( ( [https://github.com/cjhutto/vaderSentiment] )) una herramienta de análisis de sentimientos basada en reglas y léxico que está específicamente en sintonía con los sentimientos expresados en las redes sociales. Si recordamos la sección [1.2] , los algoritmos para el análisis de sentimiento están basados en la utilización de un diccionario de palabras, donde cada una de ellas es clasificada en cuanto qué tan positiva o negativa son. En el cuadro [4.1] se expone un ejemplo donde las palabras más positivas tienen calificaciones más altas y las palabras más negativas tienen calificaciones más bajas.| Word | Sentiment rating |
|---|---|
| tragedy | -3.4 |
| rejoiced | 2.0 |
| insane | -1.7 |
| disaster | -3.1 |
| great | 3.1 |
| Sentiment metric | Value |
|---|---|
| Positive | 0.45 |
| Neutral | 0.55 |
| Negative | 0.00 |
| Compuesta | 0.69 |
- Negativo: 0.321
- Neutral: 0.679
- Positivo: 0.0
- Compuesto: -0.6369
| La comida es buena | La comida es BUENA | |
|---|---|---|
| Positive | 0.492 | 0.548 |
| Neutral | 0.508 | 0.452 |
| Negative | 0.00 | 0.00 |
| Compound | 0.4404 | 0.5622 |
4.2. Sistemas de Análisis Del Sentimiento y Polaridad Reputcional con BERT
Como se ha analizado anteriormente, BERT es un modelo bidireccional que se basa en la arquitectura de la transformación explicada en el artículo "Attention is all you need'' [20] además de reemplazar la naturaleza secuencial de redes neuronales (long short-term memory-LSTM [18] y gated recurrent units-GRU [21] ) por un enfoque mucho más rápido basado en la atención (Attention-based approach). Este modelo está pre-entrenado para dos tareas no supervisadas como son el modelado de lenguaje oculto (masked language modeling) y predicción de la siguiente frase (next sentence prediction). Esto permite a los programadores usar un modelo BERT previamente entrenado y ajustarlo a la tarea específica deseada, es decir, enfocarlo en la clasificación de sentimiento y la polaridad reputacional. En este punto nos centraremos en la aplicación de BERT al problema de la clasificación de texto. Está tarea supondrá clasificar cada uno de los documentos proporcionados por el dataset según su sentimiento y su polaridad. Para ello, cada documento únicamente podrá tener una etiqueta que represente su sentimiento o polaridad respecto al Bitcoin ya que utilizaremos modelos diferentes para cada una de las tareas. Esta etiqueta podrá contener uno de los siguientes tres estados:- Positivo
- Negativo
- Neutro
- BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
- BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
- BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
- BERT-Base, Multilingual Cased (New, recommended): 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
4.2.1 Implementación 1
En esta implementación se escogió el modelo BERT-Base, Uncased con 12 layers y un tokenizador convertirá todo el texto a minúsculas. Además, se usó PyTorch sobre TensorFlow, utilizando el puerto PyTorch de BERT explicado por HuggingFace en ( [https://github.com/huggingface/pytorch-pretrained-BERT] ). Según explica el autor convierte los puntos de control de TensorFlow previamente entrenados en pesos de PyTorch utilizando el script de HuggingFace. Otro paso necesario es implementar la conversión del tweet en un tipo de dato que pueda ser utilizado por BERT. Un ejemplo es la figura [4.1] donde se puede ver un proceso de conversión de la frase my dog is cute. He likes playing.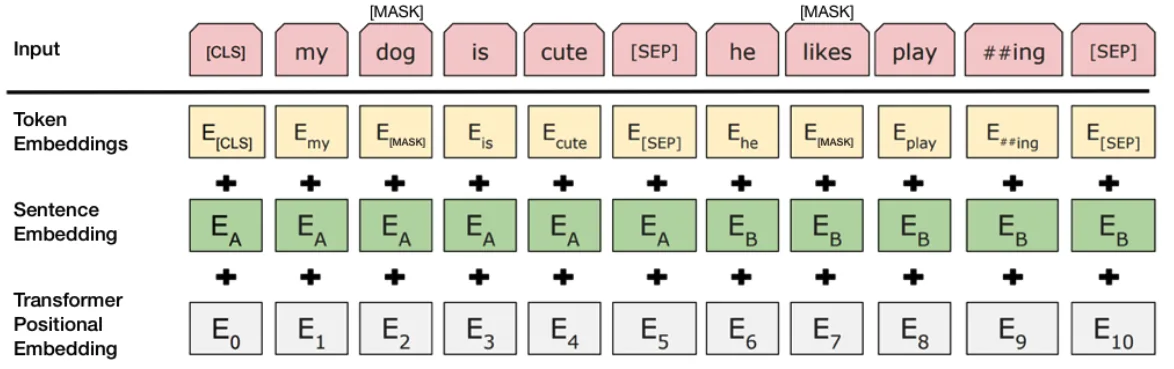
4.2.2 Implementación 2
En esta segunda implementación, hemos adaptado el código publicado por google-research en Git Hub (( [https://github.com/google-research/bert] )) dónde se expone una adaptación del algoritmo BERT. Esta implementación es muy parecida a la que nos encontramos en la sección [4.2.1] ya que la implementación 1 se basa en el código utilizado en este ejemplo y, por lo tanto, comparte gran parte del código y la configuración como, por ejemplo, el modelo pre-entrenado escogido, que ha sido el modelo BERT-Base, Uncased con 12 layers como en la implementación anterior La primera característica para destacar en la implementación de Google Research es como ha agregado TF Hub (( [enlace] )) como un módulo agregado a las tuberías de texto de Tensorflow. El siguiente punto es como transforma los tweets en un formato que BERT entienda. Para ello primero se selecciona como y que datos se utilizarán como entrada en el constructor provisto en la biblioteca BERT. Este constructor tiene tres componentes de entrada que son:- Text_a es el texto que queremos clasificar, es decir, el tweet.
- Text_b se usa si estamos entrenando un modelo para comprender la relación entre oraciones (es decir,¿text_b es una traducción de text_a? ¿text_b es una respuesta a la pregunta formulada por text_a?). Esto no se aplica en el proyecto, por lo tanto, estará en blanco para lo ser utilizado.
- Label es la etiqueta que se le otorga al tweet. En la implementación utilizada es Verdadero o Falso
- Convertir a minúsculas el tweet
- Dividir las palabras en WordPieces (es decir, "callin'' )
- Asignar índice a las palabras
- Agregar los tokens especiales "CLS'' y "SEP''
4.3. Sistema Análisis Polaridad Reputacional con BERT utilizando BitTweet etiquetado manualmente
En esta sección adaptaremos ambas implementaciones para predecir la polaridad reputacional de un conjunto de tweets. Como ya se especificó anteriormente, para analizar la polaridad reputacional vamos a etiquetar los tweets de 3 formas posibles: positivo, negativo y neutro. Esta nueva necesidad ha exigido adaptar ambas implementaciones de la siguiente forma:- En la implementación 1, hemos convertido las etiquetas en vectores de ceros y unos, de forma que un tweet puede tener una de las siguientes etiquetas:
- positivo=
- negativo=
- neutro=
- En la implementación 2, hemos convertido las etiquetas en números del 0 al 2, de forma que un tweet puede tener una de las siguientes etiquetas:
- positivo=
- negativo=
- neutro=
- Implementación 1: 75% Tasa de acierto
- Implementación 2: 87,03% Tasa de acierto
4.4. Sistema Análisis del Sentimiento con BERT utlizando BitTweet etiquetado manualmente
En esta sección adaptaremos de forma idéntica ambas implementaciones, es decir, modificaremos la implementación para adaptarla el múltiple etiquetado, aunque con un objetivo diferente. En esta ocasión modificaremos el etiquetado de los tweets para predecir el sentimiento acorde al sistema establecido de 3 etiquetas: positivo, negativo y neutro. Para llevar a cabo esta tarea adaptaremos el código de la siguiente forma- En la implementación 1, hemos convertido las etiquetas en vectores de ceros y unos, de forma que un tweet puede tener una de las siguientes etiquetas:
- positivo=
- negativo=
- neutro=
- En la implementación 2, hemos convertido las etiquetas en números del 0 al 2, de forma que un tweet puede tener una de las siguientes etiquetas:
- positivo=
- negativo=
- neutro=
- Implementación 1: 83% Tasa de acierto
- Implementación 2: 90% Tasa de acierto
4.5. Discusión sobre las dos implementaciones
Como se pudo comprobar en este capítulo, ambos códigos fueron implementados por sus desarrolladores [15] para la clasificación binaria de textos acorde a su sentimiento, es decir, únicamente podían describir si el tweet poseía un sentimiento positivo o negativo. En un principio, en este proyecto se ha escogido implementar las primeras versiones siguiendo este tipo de etiquetado para valorar ambos códigos modificando mínimamente los proyectos de los autores y, siendo lo más ajustados a la implementación original posible, ver la cantidad de tweets necesarios para crear el modelo en una tasa de éxito del 80 por ciento. Siguiendo esta filosofía, el proyecto necesitaba un dataset de pruebas y etiquetado que nos pudiera servir de base para crear los modelos y testearlos. El tweet utilizado en las pruebas únicamente podrá almacenar dos tipos de etiquetas: positivo o negativo. Una vez creado el dataset y un método para distribuir el conjunto de datos entre entrenamiento y test, se ha creado diferentes modelos con diferente número de tweets para analizar que configuración más adecuada para el proyecto. Para poder comparar los resultados se ha utilizado la Tasa de Acierto y se ha generado la tabla [4.5] donde ya se puede comprobar que la segunda implementación tiene un porcentaje de acierto que la primera. El primer detalle al analizar los resultados ha sido la disminución de la tasa de acierto en la primera implementación al aumentar la cantidad de tweets de entrenamiento en 1500 casos. Esto puede ser debido a que el aumento en la diversidad de los tweets utilizados ha generado una pérdida de eficiencia en el modelo. Además, revisando la cantidad de tweets positivos y negativos que hay en las pruebas, se puede comprobar como la tasa de tweets etiquetados como positivos supera con creces la de tweets etiquetados como negativos. Esto hecho es muy importante, ya que un modelo que etiquete todo el tweet como positivos (caso 1 en la implementación 1) obtiene un porcentaje de acierto del 85,2. Este detalle, unido con que los tweets de entrenamiento y de test eran muy próximos en el tiempo, hacen entrever que los tests aplicados han sido útiles para aprender y validar el funcionamiento del algoritmo, pero no definitorios sobre su validez.| Número Tweet Entrenamiento | Implementación 1 Porcentaje Acierto | Implementación 2 Porcentaje Acierto |
|---|---|---|
| 250 | 85,2 | 87,2 |
| 750 | 87,8 | 87,4 |
| 1000 | 88 | 89,3 |
| 1500 | 85,9 | 89,2 |
- Se utilizarán 3 etiquetas, positivo, negativo y neutral, que definirán la polaridad reputacional del tweet respecto al Bitcoin.
- La cantidad de tweets de cada grupo tendrá que ser como mínimo del 15 por ciento
- Los tweets etiquetados serán seleccionados aleatoriamente, es decir, podrán corresponder a diferentes días o meses del año 2019.
| Tasa de Acierto | Análisis del sentimiento | Polaridad Reputacionl |
|---|---|---|
| Implementación 2 | 90 | 87 |
| Implementación 1 | 83 | 75 |
4.6. Sistema de predicción bursátil
Con los algoritmos analizados y validados, el siguiente punto del proyecto ha consistido en predecir la polaridad reputacional y el sentimiento de la información recopilada en la sección [3] para investigar si existe una correlación con el precio del bitcoin. Para cumplir este objetivo, el primer punto era determinar que parte del dataset era óptimo para el propósito de la sección. Tal y como se documentó en el proceso de etiquetado, los tweets utilizados fueron escritos durante los meses de abril, mayo y junio y, por lo tanto, se ha decidido utilizar toda la información obtenidos desde el 1 de abril hasta el 31 de julio, con el objetivo de que los datos obtenidos durante los tres primeros meses sirvan de entrenamiento y los datos de julio como test. Una vez escogido el subconjunto del dataset a analizar, el siguiente paso fue medir la cantidad de tweets valorados como positivos, negativos y neutrales por ambos modelos con el objetivo de crear un nuevo modelo que pudiera predecir la acción del precio del BitCoin. Para ello, hemos dividido los tweets por hora y el resultado se ha almacenado en una base de datos Mysql para su futura interpretación. El siguiente punto del proceso fue convertir la información extraída en datos con el objetivo de ser interpretados por el modelo LSTM (Long short-term memor). Este proceso consistirá en normalizar la cantidad de tweets positivos, negativos y neutrales catalogados por cada hora junto con la cantidad de tweets total escritos. Como variable objetivo utilizaremos el precio del Bitcoin. Posteriormente, los datos normalizados serán divididos en dos subconjuntos, el de entrenamiento con 1500 horas y el de test con 1255 horas (con un retraso de 3 horas). Respecto al modelo, como hemos comentado previamente se ha generado un sistema LSTM con los siguientes parámetros de configuración:- Epochs: 50
- Validation split: 0.2
- Batch size: 12
5.Resultados experimentales
Cómo interpretar estas métricas
La exactitud no basta con clases desiguales. Debe leerse junto a precisión, recall y F1 por clase, matrices de confusión y evaluación cronológica fuera de muestra. Una correlación no demuestra causalidad ni rentabilidad.
5.1. Polaridad Reputacional
Una vez se ha generado el modelo, se han utilizado 346 tweets etiquetados como conjunto de testeo. Los resultados obtenidos se pueden comprobar en el cuadro [5.1] expuesto a continuación:| Medidas | Negativo 0 | Positivo 1 | Neutro 2 |
|---|---|---|---|
| Precision | 0.853 | 0.812 | 0.872 |
| Recall | 0.617 | 0.759 | 0.963 |
| F1 | 0.716 | 0.785 | 0.915 |
- RT @Analyst_G: The whole semiconductor business looks like bitcoin and tulip mania... ( [https://t.co/824IIxW6Nh] )
- No that’s what gold is. Bitcoin has yet to prove itself in a single down cycle.
- "Bitcoin is going to get pumped to where the whales are happy. Then the altcoins are going to get pumped. The biggest pump of all will happen to #XR''
- Negativos: 302 que es un 17 por ciento del total.
- Neutrales: 820 que es un 45 por ciento del total.
- Positivos: 684 que es un 38 por ciento del total.
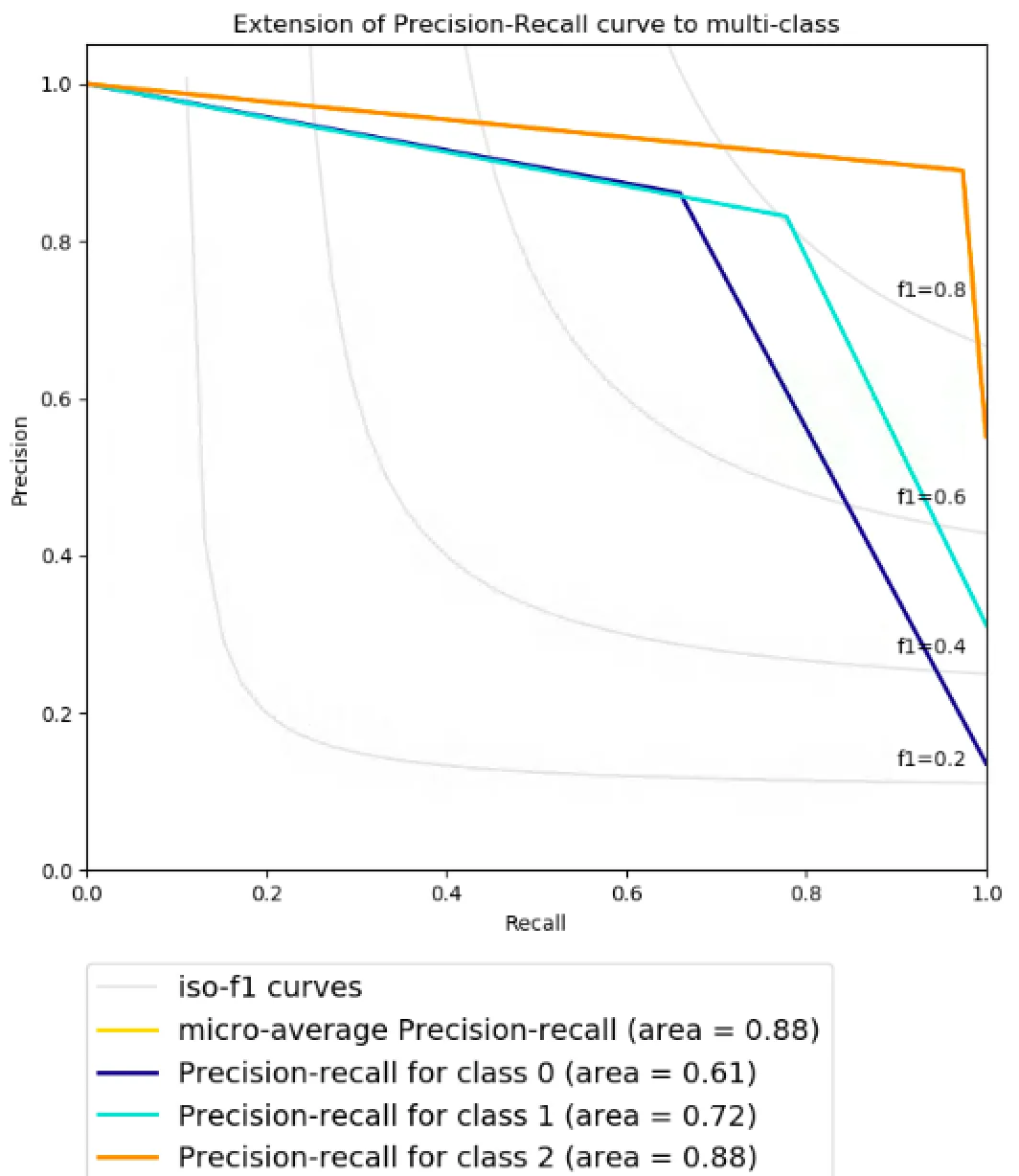
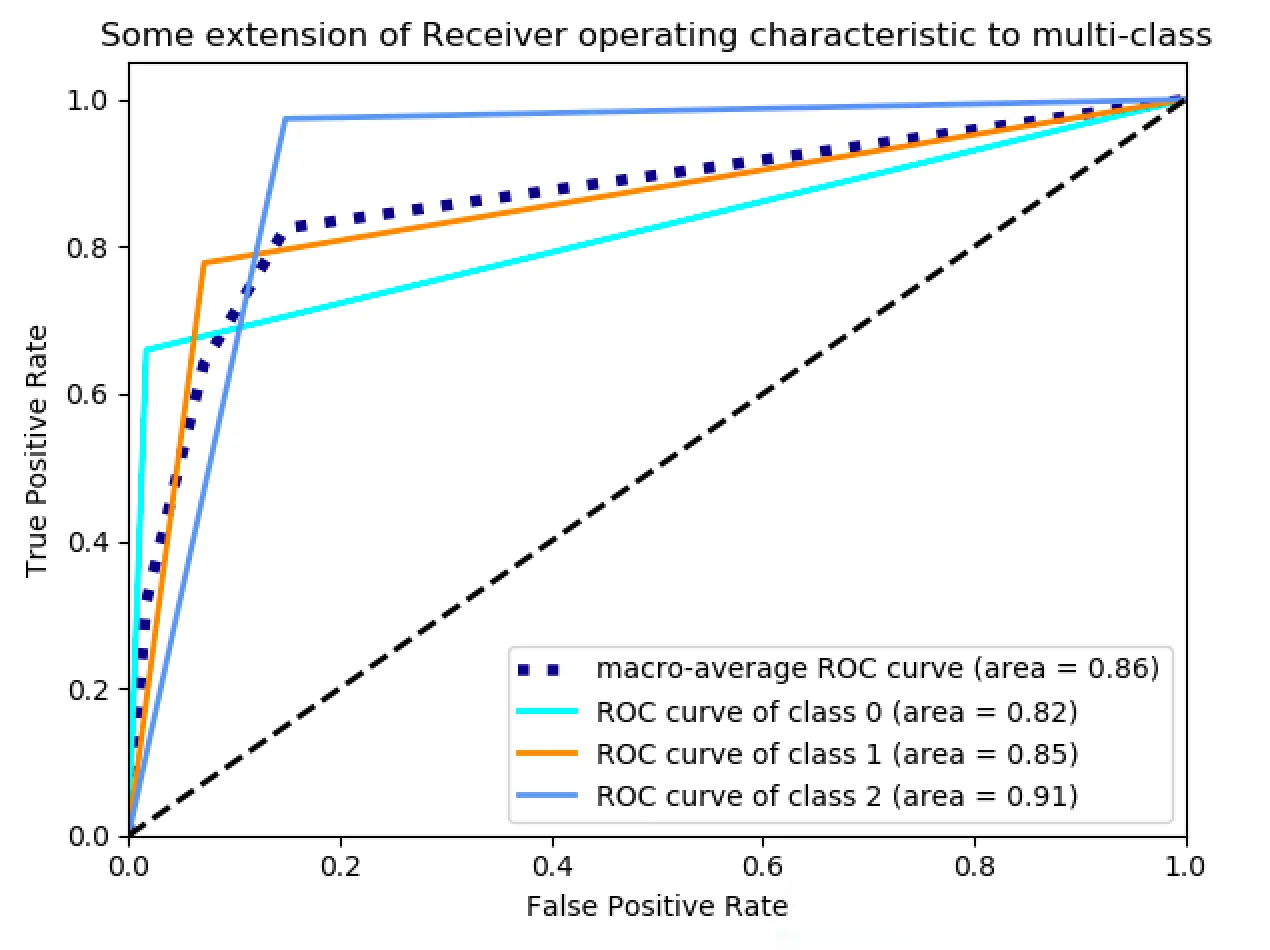
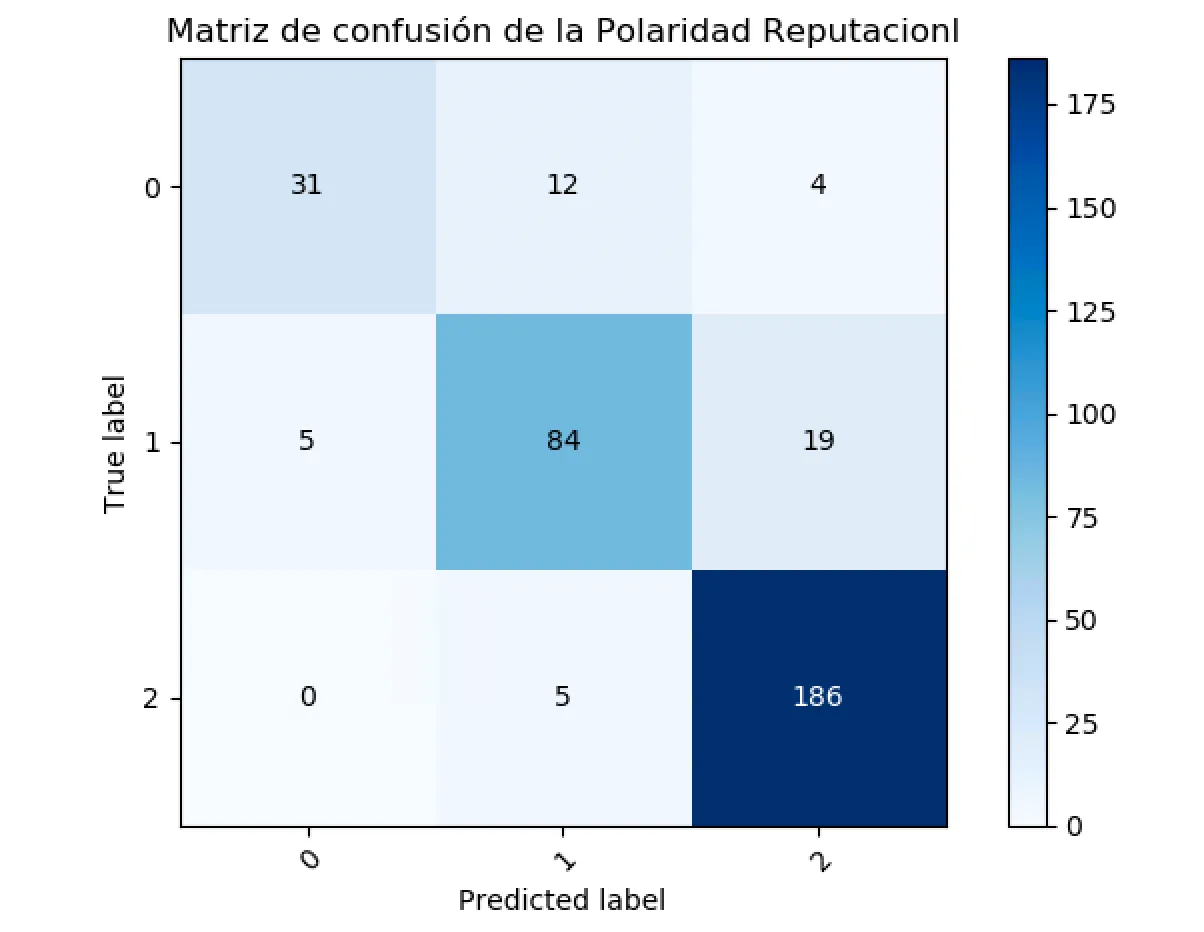
5.2. Análisis de sentimientos
En el siguiente punto se analizarán las métricas obtenidas por el modelo utilizado para la predicción del sentimiento. Para este punto se han utilizado 349 tweets como conjunto de testeo y los resultados obtenidos se pueden comprobar en el cuadro [5.2] expuesto a continuación:| Medidas | Negativo 0 | Positivo 1 | Neutro 2 |
|---|---|---|---|
| Precision | 0.843 | 0.875 | 0.940 |
| Recall | 0.908 | 0.875 | 0.912 |
| F1 | 0.874 | 0.875 | 0.926 |
- Negativos: 414 que es un 22 por ciento del total.
- Neutrales: 738 que es un 40 por ciento del total.
- Positivos: 700 que es un 38 por ciento del total.
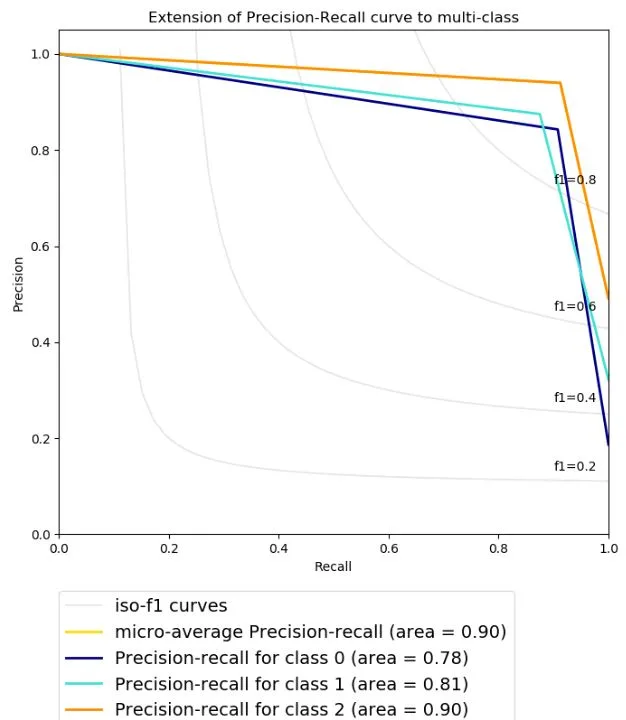
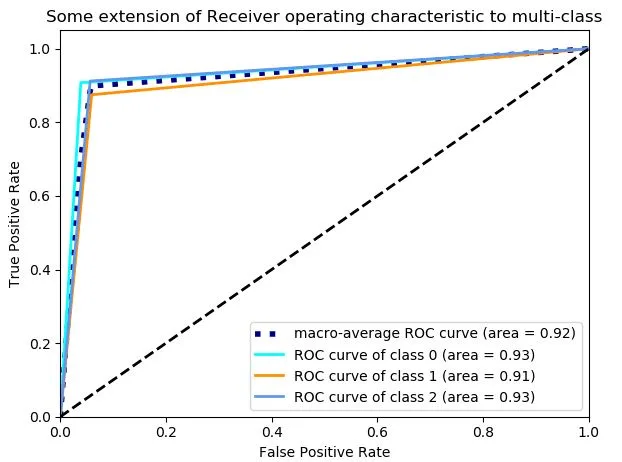
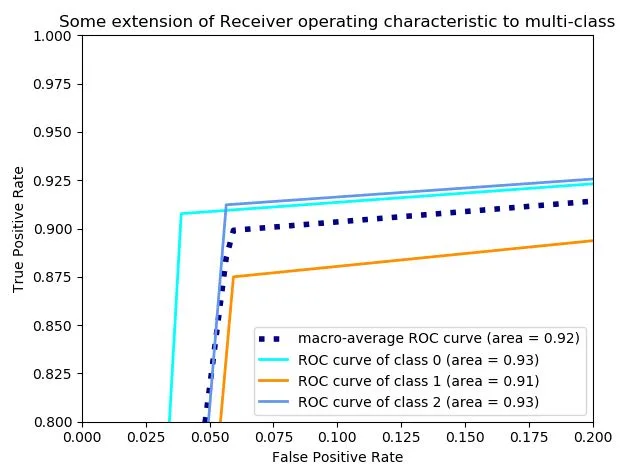
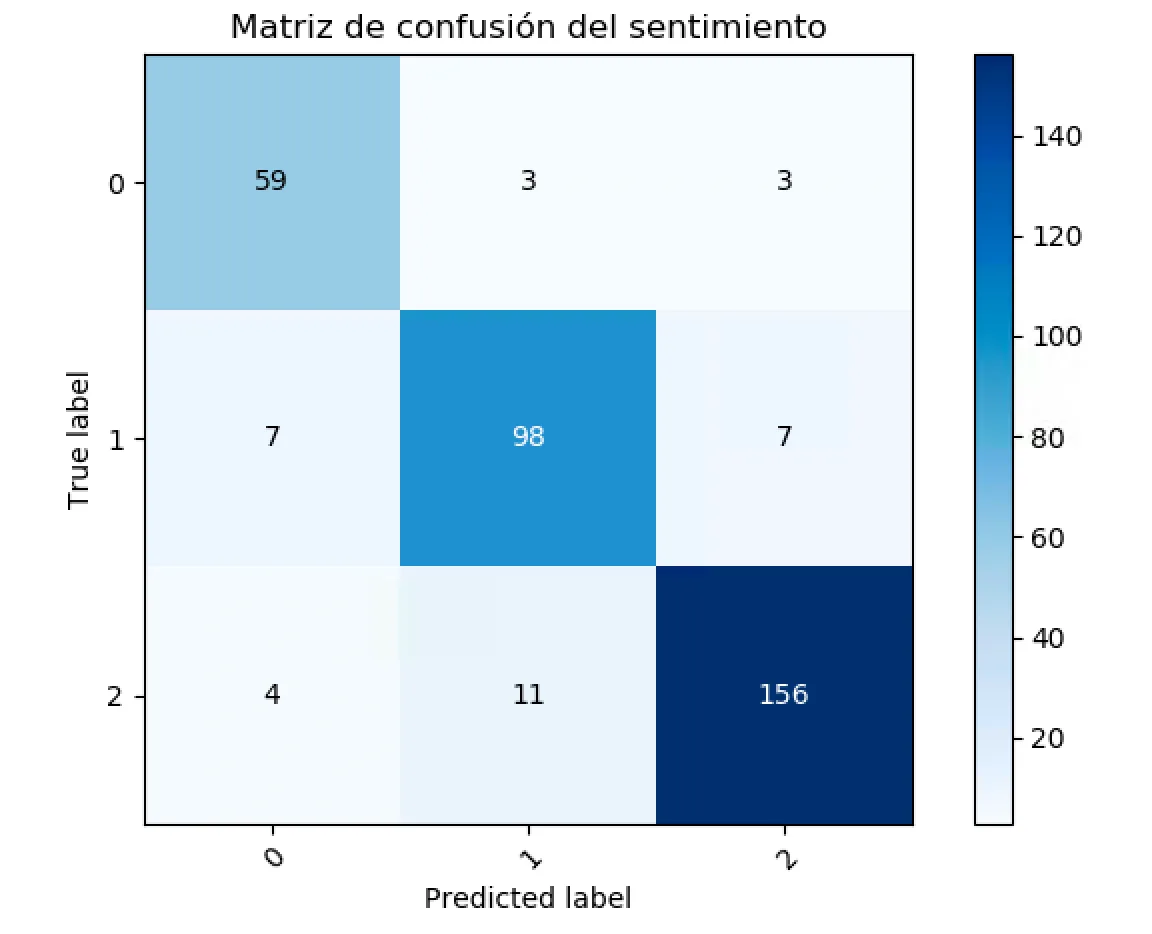
5.3. Predicción de valores bursátiles
En este apartado se valorarán los resultados obtenidos a través de la predicción realizada con los datos generados de la sección [4.6] . El primer punto ha sido generar un gráfico de correlación de todas las características que se incluyeron en el modelo de predicción para la polaridad reputacional, es decir, la relación que existe entre la cantidad de tweets positivos, negativos, neutrales, la cantidad de tweets total y el precio del Bitcoin. Esto dará una indicación más clara de las características que pueden ser más importantes que otras. Para ello empezaremos con la figura [5.8] donde se mostrara la correlación entre las diferentes variables.
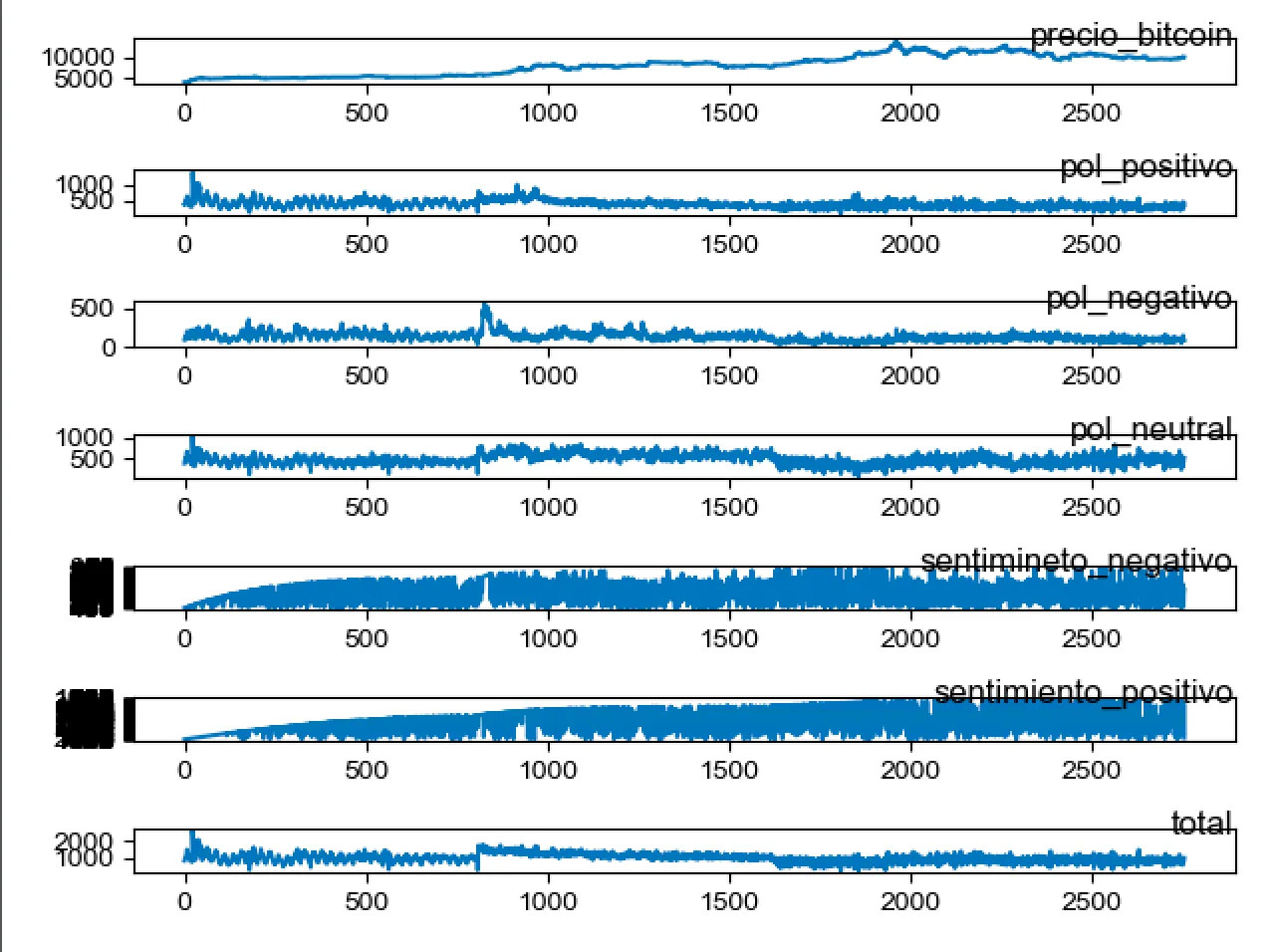
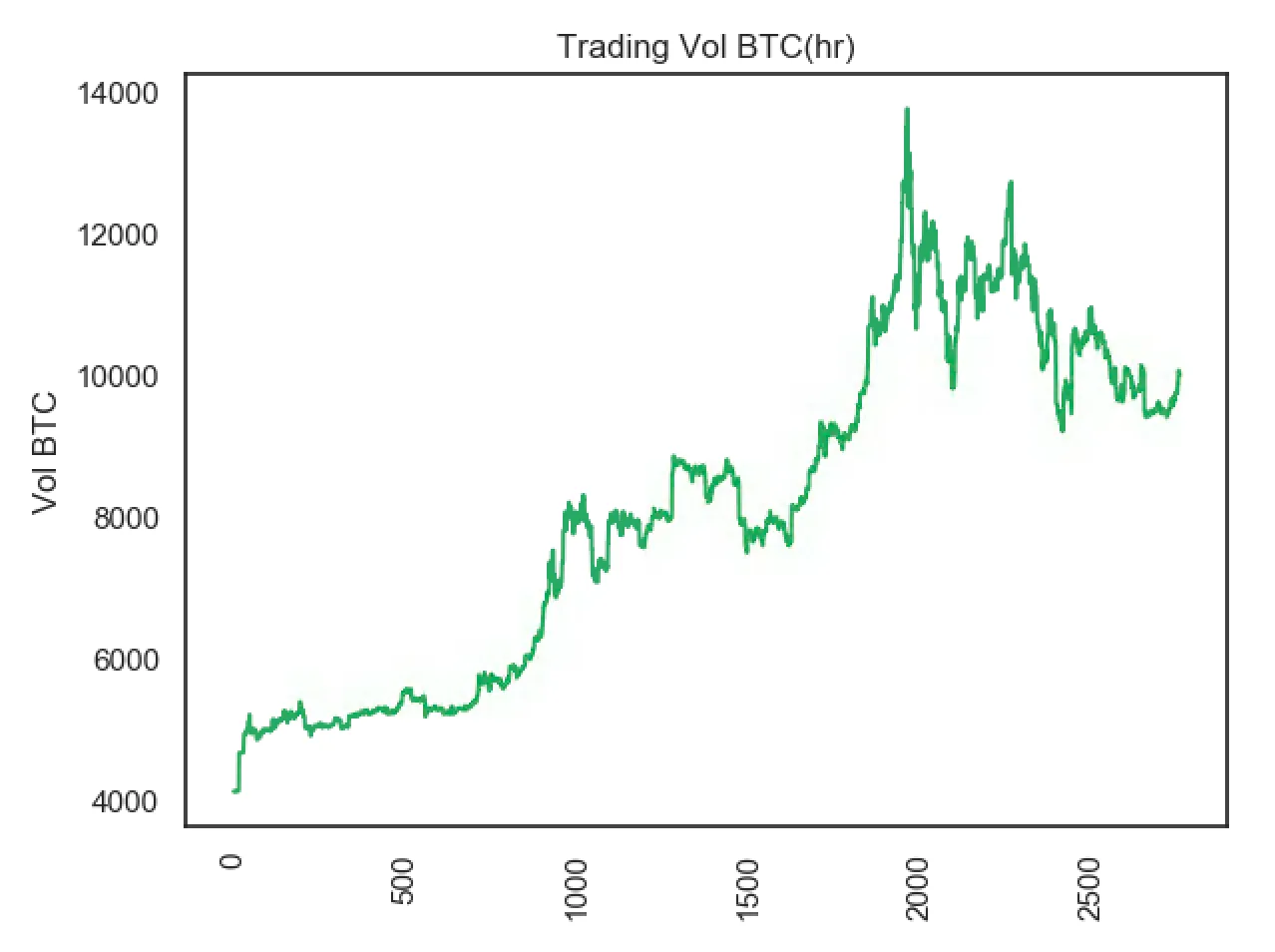
- Prueba MSE: 5498.255
- Prueba RMSE: 74.150
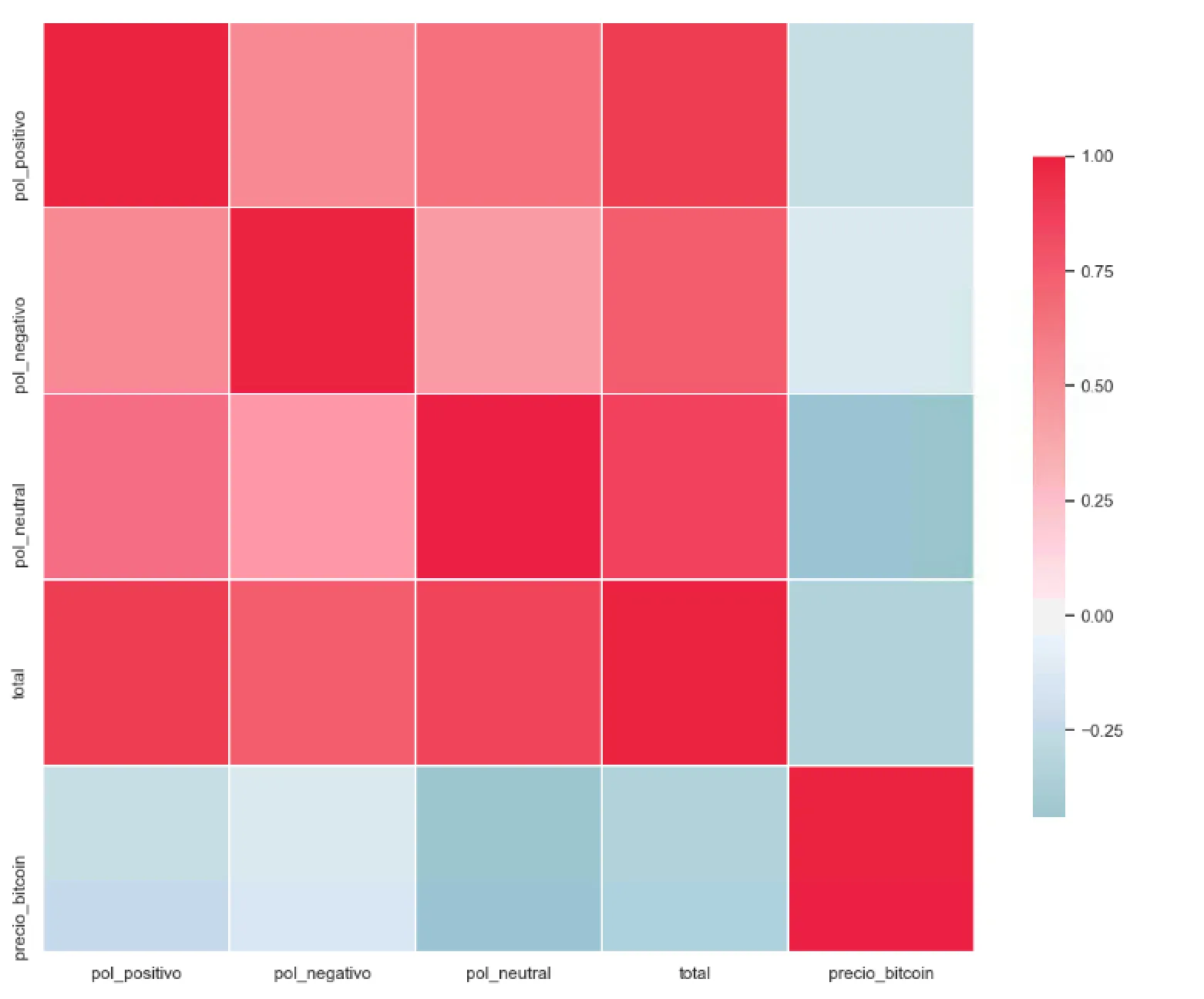
- Prueba MSE: 28742.381
- Prueba RMSE: 169.536
| Medidas | Sentimiento | Polaridad Reputacionl |
|---|---|---|
| MSE | 28742.381 | 5498.255 |
| RMSE | 169.536 | 74.150 |
6.Conclusiones
Este capítulo se divide en dos secciones, la primera destinada a las conclusiones del proyecto y la segunda a trabajos futuros.6.1. Conclusiones
Aunque el análisis de sentimiento es la herramienta de Procesamiento del Lenguaje Natural más utilizada para la gestión de reputación online, se ha demostrado en la sección [3.4] que los sentimientos de un texto que habla del Bitcoin y sus implicaciones reputacionales para esa entidad son cosas diferentes; de hecho, la mayoría de los textos con implicaciones reputacionales son polar facts, es decir, información factual sin sentimientos explícitos. A partir de esta afirmación, el objetivo de la tesis ha sido comparar la utilidad del análisis automático de polaridad reputacional respecto al análisis de sentimientos para predecir el valor del Bitcoin, bajo la hipótesis de que el análisis reputacional debería tener una relación más directa con la cotización y por tanto ser un mejor predictor de su valor bursátil. Para nuestra experimentación hemos seleccionado el bitcoin (un valor altamente volátil y por tanto un reto desde el punto de vista de los modelos predictivos) y Twitter como fuente textual, por ser una de las redes sociales en las que se puede recolectar datos de forma más sencilla y, sobre todo, por su inmediatez, que es necesaria a la hora de establecer correlaciones temporales con un valor muy fluctuante como es la cotización del Bitcoin. Como no existía ningún dataset adecuado para nuestro objetivo, nuestra primera contribución ha sido desarrollar BitTweet, un dataset de tweets que mencionan bitcoin anotado manualmente respecto a sentimiento y polaridad reputacional y enlazado con la cotización del Bitcoin. Para ello se ha utilizado una base de datos con 792.792 registros, es decir, una colección de casi 800.000 tweets en ingles sobre el Bitcoin y 20604 registros económicos sobre la criptomoneda comprendidos desde marzo hasta agosto del año 2019. Toda esa información se puede consultar en la sección [3] Las anotaciones manuales de este dataset nos permiten cuantificar la diferencia entre análisis de sentimiento y polaridad reputacional (algo que no había sido hecho previamente), evaluar modelos de predicción de sentimiento y polaridad reputacional, y evaluar modelos de predicción de valor bursátil a partir de tweets. Nuestra segunda contribución ha sido la aplicación del estado del arte en Procesamiento del Lenguaje Natural (en particular, los contextual word embeddings en su implementación en el sistema BERT) a la estimación de la polaridad reputacional de los tweets y a la predicción de valores bursátiles, comparándola con el análisis del sentimiento. Nuestros resultados confirman nuestra hipótesis, mostrando que la polaridad reputacional es mejor predictor que el análisis de sentimientos como se puede comprobar en la sección [5.3] . Estos resultados sugieren que los sistemas de análisis reputacional deberían reducir su dependencia del software de análisis de sentimientos y sustituirlo por un análisis directo de las implicaciones reputacionales de los textos. Todos los experimentos realizados en el proyecto han sido comparados y testeados con VADER, utilizado como baseline a lo largo del proyecto. Como hemos comentado en la sección [1.4.1] , el Bitcoin no está respaldada por ninguna entidad o nación, únicamente por los usuarios que la utilizan y le otorgan un valor en cada transacción. Estos mismos usuarios son los que publican y comparten en sus redes sociales noticias tanto positivas como negativas sobre la criptomoneda. Por ese motivo, en el caso del Bitcoin no podemos utilizar el típico análisis basado en indicadores económicos habituales, sino deberemos adaptarnos a este nuevo escenario y utilizar indicadores como la polaridad reputacional para emitir estas predicciones.6.2. Trabajos futuros
En esta sección se comentarán los futuros trabajos a realizar a partir de las hipótesis confirmadas en el proyecto. La primera opción sería trabajar en el proceso de etiquetado de la polaridad reputacional y el sentimiento, interviniendo más personas o comparando el resultado con otros modelos generados por otros etiquetadores. También se podría utilizar dataset originados en otros idiomas, para ver el porcentaje de acierto en la predicción de BERT utilizando el modelo pre-entrenado en chino o castellano. Respecto al punto de vista de la implementación, se podría aumentar el conjunto de datos utilizados como entrenamiento o, incluso, se podría comparar con otras implementaciones o otros algoritmos como OPENAI GPT-2 para validar que BERT es el algoritmo proporciona mayores resultados para esta tarea. Respecto al Bitcoin, otro trabajo futuro podría ser investigar la correlación de la polaridad reputacional de la moneda con el valor bursátil de otra criptomoneda como Ethereum. También se podría aplicar la misma investigación a otro valor bursátil un poco menos volátil, para ver la eficacia en esa situación. Por último, la fuente de datos utilizada ha sido Twitter, en futuros trabajos se puede utilizar otro tipo de datos como puede ser Facebook, Blogs o Webs de noticias o , incluso utilizar BitTweet desde el punto de vista de la obra [Estimating reputation polarity on microblog posts] y valorar más aquellas opiniones con más retweets o interacciones para realizar las predicciones.Bibliografía
14.Titulo
LSTM Model predicting Bitcoin with Tweet Volume \& Sentiment
Autor
Simpson, Paul
Publicacion
Medium
15.Titulo
Multi-label Text Classification using BERT – The Mighty Transformer
Autor
Trivedi, Kaushal
Publicacion
Medium
16.Titulo
Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
Autor
Publicacion
Google AI Blog
25.Titulo
Bitcoin: planteamiento y protocolo
Autor
Víctor Díaz Marco
Publicacion
Víctor Díaz Marco
26.Titulo
Bitcoin y ether se derrumban en los últimos días ante las amenazas de China y Rusia
Autor
elEconomista.es
Publicacion
elEconomista.es
29.Titulo
Using VADER to handle sentiment analysis with social media text
Autor
Burchell, Jodie}}
Publicacion
Standard error Full Atom
31.Titulo
Docs - Twitter Developers
Autor
Publicacion
Twitter
33.Titulo
Visualizing Polarity-based Stances of News Websites
Autor
Masaharu Yoshioka and
Publicacion
Proceedings of the Second International Workshop on Recent Trends