Ejemplo de un etiquetado manual.
Etiquetadores clásicos y evaluación actual
TreeTagger y Stanford POS Tagger siguen siendo baselines históricos útiles. En una comparación actual hay que unificar etiquetas y tokenización, reservar un gold test, comunicar errores por etiqueta y comparar con un pipeline mantenido. La anotación manual necesita instrucciones escritas y acuerdo entre anotadores.
Introducción
En la siguiente página web: https://nlp.stanford.edu/links/statnlp.html , en la sección "Part of Speech Taggers" puedes encontrar numerosos etiquetadoresestadísticos. Muchos de ellos se basan en modelos distintos (HMMs, Support Vector Machine,etc.), utilizan distintos corpus de entrenamiento, sirven para distintos idiomas, etc. En esta tarea debes comparar el comportamiento de al menos dos de ellos. Los estudiaremos, describiremos y utilizaremos para realizar el etiquetado de un pequeño texto. Después compararemos los resultados: etiquetas utilizadas por cada etiquetador y precisión del etiquetado.2. Descripción de los etiquetadores seleccionados
Los etiquetadores escogidos han sido:- TreeTagger
- Stanford Log-linear Part-Of-Speech Tagger
- tTAG
2.1 TreeTagger
TreeTagger es una herramienta de etiquetado de texto, análisis de las oraciones y extracción del lema. Fue desarrollado por Helmut Schmid en el proyecto TC del Instituto de Lingüística Computacional de la Universidad de Stuttgart con el objetivo de ser utilizado para el etiquetado y lematización de voz. Para ejecutarlo, es necesario utilizar el modelo para el idioma seleccionado (un fichero conocido como "parameters" y con la extensión .par) que se pueden obtener desde la propia página web de TreeTagger. Dentro de esta web, podremos encontrar diferentes parameters que podremos utilizar para analizar con el programa textos en inglés, francés, alemán, italiano, español, ruso, búlgaro, holandés, estonio, finlandés, gallego, latín, mongol, polaco, eslovaco y swahili. Para un idioma donde no existe un modelo la herramienta ofrece la posibilidad al usuario de crear un nuevo modelo. Para ello es necesario etiquetar manualmente un texto de ejemplo y luego ejecutar un programa de entrenamiento (provisto con TreeTagger) para crear el modelo.2.1.1 Instalación
En mi caso, lo he instalado la aplicación en un ordenador personal con Windows 7, utilizando el instalador descargado en la siguiente url https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/Para instalarlo he realizado los siguientes pasos:- Primero de todo, es necesario instalar el interprete de Perl que lo podemos descargar de la siguiente url http://www.activestate.com/activeperl/
- El siguiente punto es extraer los ficheros del documento zip descargado de la web en el directorio C:/. del ordenador utilizado.
- Una vez descomprimido, el siguiente paso es descargarse de la web los ficheros llamados parámetros para los idiomas que necesitemos. Los ficheros deben tener una estructura -utf8.par y se deben almacenar en el subdirectorio TreeTagger/lib.
- Tenemos que añadir como variable de entorno la siguiente ruta C:/TreeTagger/bin
- Posteriormente, es necesario abrir un terminal de Windows y ejecutar los siguientes comandos
set PATH=C:\TreeTagger\bin;%PATH% cd c:\TreeTagger
- Por último, ya podemos ejecutar el programa con el sguiente comando
tag-<lenguage><namefile>
3. Stanford Log-linear Part-Of-Speech Tagger
Un Tagger Part-Of-Speech (POS Tagger) es una herramienta que se encarga de clasificar las diferentes partes de un texto escrito de un idioma determinado. Este software tiene como finalidad clasificar cada palabra dependiendo de su funcionalidad, ya que nos presentará cada una de ellas como un sustantivo, verbo, adjetivo, etc. e incluso tiene la capacidad de usar etiquetas POS más precias como "sustantivo-plural". Esta implementado en Java y utiliza los etiquetadores log-line descritos en Enriching the Knowledge Sources Used in a Maximum Entropy Part-of-Speech Tagger Para poder ejecutar este programa es necesario:- Una versión de Java 1.8 o superior.
- Entre 60 y 200 MB de memoria para el programa
- Al menos 1 GB de memoria para almacenar el modelo encargado de entrenar el etiquetador.
4. tTAG
Para empezar, tTAG fue implementado por Infogistics, una compañía internacional de Edimburgo creada por expertos en el campo de minería de texto y búsqueda en documentos. Su principal producto, tTAG, es un etiquetador de textos que puede manejar tanto texto codificado en ASCII como texto marcado XML. tTAG incorpora un tokenizer (tNORM) encargado de segmentar el texto en palabras y oraciones. En aquellos casos que el usuario necesite utilizar su propio tokenizer, la aplicación permite sustituir tNORM por uno de elaboración propia. Desde el punto morfológico, tTAG utiliza un léxico que se puede extender fácilmente para incluir palabras nuevas. Cuando el software se encuentra con una palabra desconocida, tTAG ejecuta un software de predicción que permite predecir y etiquetar las palabras desconocidas. Esta capacidad puede ser reentrenada por el usuario para nuevos sublenguajes. Gracias a esta capacidad, tTAG logra una precisión del 96% al 98% de aciertos en aquellas palabras que se encuentran en el léxico y un 88-92% de precisión en palabras desconocidas. tTAG permite utilizar tanto los recursos previamente entrenados basados en el conjunto de etiquetas de Penn Treebank que te proporciona la aplicación como también desarrollar recursos propios utilizando un conjunto de etiquetas propio. Al ejecutar tTAG, simplemente debe especificar qué archivo de recursos desea usar durante el etiquetado. Al analizar texto marcado en SGML/XML, tTAG puede marcar el texto completo o solo marcar algunas secciones determinadas del documento XML (por ejemplo, solo para etiquetar párrafos, y no encabezados ni subtítulos). También es posible solicitar a tTAG que emita el texto etiquetado como XML.
<SENTENCE>
<W TAG="PPS">He</W>
<W TAG="VBZ">books</W>
<W TAG="NNS">tickets</W>
</SENTENCE>
Respecto el analizador sintáctico del tTag cabe mencionar que utiliza la información del documento y emplea gramáticas sensibles al contexto para detectar los límites de los grupos sintácticos. El analizador deja toda la información añadida previamente en el texto y crea elementos estructurales que incluyen palabras del fragmento:
<NG>Este hombre</NG>
<VG>canta</VG>
5. Texto de prueba utilizado.
Para realizar esta tarea he elegido el siguiente texto en ingles extraído del libro El Principito de ANTOINE DE SAINT-EXUPÉRY:Once when I was six years old I saw a magnificent picture in a book, called True Stories from Nature, about the primeval forest. It was a picture of a boa constrictor in the act of swallowing an animal. Here is a copy of the drawing.
Basándome en que los tres textos tienen la capacidad de etiquetar textos en diferentes idiomas, he buscado el mismo texto en la versión en castellano para analizarlo. El texto utilizado es el siguienteCuando yo tenía seis años vi en un libro sobre la selva virgen que se titulaba "Historias vividas", una magnífica lámina. Representaba una serpiente boa que se tragaba a una fiera.
6.Resultado del etiquetado con cada etiquetador seleccionado.
6.1 TreeTagger
Primero de todo, en el cuadro 1 podemos consultar que tipo de etiquetas utiliza TreeTagger en ingles, en el cuadro 2 las etiquetas que utiliza en castellano, en el cuadro 3 se representará el resultado en inglés y, por último, en el cuadro 4 se representará el resultado en castellano.| POS Tag | Description | Example | |
|---|---|---|---|
| CC | coordinating conjunction | and, but, or, \ | |
| CD | cardinal number | 1, three | |
| DT | determiner | the | |
| EX | existential there | there is | |
| FW | foreign word | d'œuvre | |
| IN | preposition/subord. conj. | in,of,like,after,whether | |
| IN/that | complementizer | that | |
| JJ | adjective | green | |
| JJR | adjective, comparative | greener | |
| JJS | adjective, superlative | greenest | |
| LS | list marker | (1), | |
| MD | modal | could, will | |
| NN | noun, singular or mass | table | |
| NNS | noun plural | tables | |
| NP | proper noun, singular | John | |
| NPS | proper noun, plural | Vikings | |
| PDT | predeterminer | both the boys | |
| POS | possessive ending | friend's | |
| PP | personal pronoun | I, he, it | |
| PP\$ | possessive pronoun | my, his | |
| RB | adverb | however, usually, here, not | |
| RBR | adverb, comparative | better | |
| RBS | adverb, superlative | best | |
| RP | particle | give up | |
| SENT | end punctuation | ?, !, . | |
| SYM | symbol | @, +, *, \textasciicircum, |, = | |
| TO | to | to go, to him | |
| UH | interjection | uhhuhhuhh | |
| VB | verb be, base form | be | |
| VBD | verb be, past | was|were | |
| VBG | verb be, gerund/participle | being | |
| VBN | verb be, past participle | been | |
| VBZ | verb be, pres, 3rd p. sing | is | |
| VBP | verb be, pres non-3rd p. | am|are | |
| VD | verb do, base form | do | |
| VDD | verb do, past | did | |
| VDG | verb do gerund/participle | doing | |
| VDN | verb do, past participle | done | |
| VDZ | verb do, pres, 3rd per.sing | does | |
| VDP | verb do, pres, non-3rd per. | do | |
| VH | verb have, base form | have | |
| VHD | verb have, past | had | |
| VHG | verb have, gerund/participle | having | |
| VHN | verb have, past participle | had | |
| VHZ | verb have, pres 3rd per.sing | has | |
| VHP | verb have, pres non-3rd per. | have | |
| VV | verb, base form | take | |
| VVD | verb, past tense | took | |
| VVG | verb, gerund/participle | taking | |
| VVN | verb, past participle | taken | |
| VVP | verb, present, non-3rd p. | take | |
| VVZ | verb, present 3d p. sing. | takes | |
| WDT | wh-determiner | which | |
| WP | wh-pronoun | who, what | |
| WP\$ | possessive wh-pronoun | whose | |
| WRB | wh-abverb | where, when | |
| : | general joiner | ;, -, -- | |
| \$ | currency symbol | \$, £ |
Cuadro.1 Etiquetas utiliza TreeTagger en ingles
| EjemploEtiquetaTreecast Tag | Description |
|---|---|
| ABR | abreviation |
| ADJ | adjective |
| ADV | adverb |
| DET:ART | article |
| DET:POS | possessive pronoun (ma, ta, …) |
| INT | interjection |
| KON | conjunction |
| NAM | proper name |
| NOM | noun |
| NUM | numeral |
| PRO | pronoun |
| PRO:DEM | demonstrative pronoun |
| PRO:IND | indefinite pronoun |
| PRO:PER | personal pronoun |
| PRO:POS | possessive pronoun (mien, tien, …) |
| PRO:REL | relative pronoun |
| PRP | preposition |
| PRP:det | preposition plus article (au,du,aux,des) |
| PUN | punctuation |
| PUN:cit | punctuation citation |
| SENT | sentence tag |
| SYM | symbol |
| VER:cond | verb conditional |
| VER:futu | verb futur |
| VER:impe | verb imperative |
| VER:impf | verb imperfect |
| VER:infi | verb infinitive |
| VER:pper | verb past participle |
| VER:ppre | verb present participle |
| VER:pres | verb present |
| VER:simp | verb simple past |
| VER:subi | verb subjunctive imperfect |
| VER:subp | verb subjunctive present |
Cuadro.2 Etiquetas utiliza TreeTagger en Castellano
| Texto Original | Etiqueta | Raiz |
|---|---|---|
| Once | RB | once |
| when | WRB | when |
| I | PP | I |
| was | VBD | be |
| six | CD | six |
| years | NNS | year |
| old | JJ | old |
| I | PP | I |
| saw | VVD | see |
| a | DT | a |
| magnificent | JJ | magnificent |
| picture | NN | picture |
| in | IN | in |
| a | DT | a |
| book | NN | book |
| , | , | , |
| called | VVD | call |
| True | NP | True |
| Stories | NP | Stories |
| from | IN | from |
| Nature | NP | Nature |
| , | , | , |
| about | IN | about |
| the | DT | the |
| primeval | JJ | primeval |
| forest | NN | forest |
| . | SENT | . |
| It | PP | it |
| was | VBD | be |
| a | DT | a |
| picture | NN | picture |
| of | IN | of |
| a | DT | a |
| boa | NN | boa |
| constrictor | NN | constrictor |
| in | IN | in |
| the | DT | the |
| act | NN | act |
| of | IN | of |
| swallowing | VVG | swallow |
| an | DT | an |
| animal | NN | animal |
| . | SENT | . |
| Here | RB | here |
| is | VBZ | be |
| a | DT | a |
| copy | NN | copy |
| of | IN | of |
| the | DT | the |
| drawing | NN | drawing |
| . | SENT | . |
Cuadro.3 Etiquetas utiliza TreeTagger en Inglés
| Texto Original | Etiqueta | Raiz |
|---|---|---|
| Cuando | CSUBX | cuando |
| yo | PPX | yo |
| tenía | VLfin | tener |
| seis | CARD | seis |
| años | NC | año |
| vi | CARD | vi |
| en | PREP | en |
| un | ART | un |
| libro | NC | libro |
| sobre | PREP | sobre |
| la | ART | el |
| selva | NC | selva |
| virgen | NC | virgen |
| que | CQUE | que |
| se | SE | se |
| titulaba | VLfin | titular |
| " | QT | " |
| Historias | NP | Historias |
| vividas | VLadj | vivir |
| " | QT | " |
| , | CM | , |
| una | ART | un |
| magnífica | ADJ | magnífico |
| lámina | NC | lámina |
| . | FS | . |
| Representaba | VLfin | representar |
| una | ART | un |
| serpiente | NC | serpiente |
| boa | NC | boa |
| que | CQUE | que |
| se | SE | se |
| tragaba | VLfin | tragaba |
| a | PREP | a |
| una | ART | un |
| fiera | NC | fiera |
| . | FS | . |
Cuadro.4 Etiquetas utiliza TreeTagger en Castellano
6.2 Stanford Log-linear Part-Of-Speech Tagger
En la primera parte del apartado he utilizado el etiquetador Stanford Log-linear Part-Of-Speech Tagger para analizar el texto en inglés aplicando el siguiente comandojava -mx300m -classpath stanford-postagger.jaredu.stanford.nlp.tagger.maxent.MaxentTagger -modelmodels/wsj-0-18-bidirectional-distsim.tagger -textFilesample-input.txt >sample-tagged.txt
Una vez se ha ejecutado y para entender mejor su funcionamiento, he utilizado la figura 1 donde se muestran todas las etiquetas que puede generar el programa para un texto en ingles.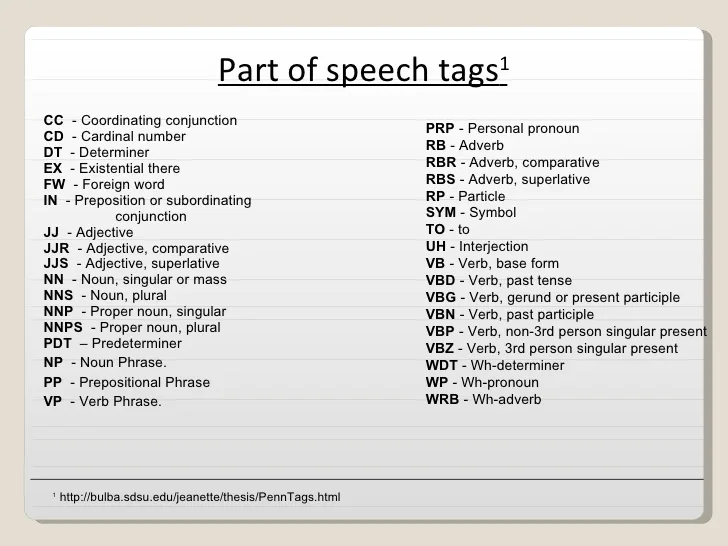
Once_RB when_WRB I_PRP was_VBD six_CD years_NNS old_JJ I_PRPsaw_VBD a_DT magnificent_JJ picture_NN in_IN a_DT book_NN ,_,called_VBN True_NNP Stories_NNP from_IN Nature_NNP ,_, about_IN the_DT primeval_JJ forest_NN ._. It_PRP was_VBD a_DT picture_NN of_IN a_DT boa_NN constrictor_NN in_IN the_DT act_NN of_IN swallowing_VBG an_DT animal_NN ._. Here_RB is_VBZ a_DT copy_NN of_IN the_DT drawing_NN ._.
Una vez realizado la prueba con el texto en inglés, he ejecutado el mismo test pero con un texto en castellano. Para conocer mejor las etiquetas utilizadas por parte de este software, recomiendo visitar la siguiente url https://nlp.stanford.edu/software/spanish-faq.shtml y el resultado obtenido ha sido el siguiente:Cuando_cs yo_pp000000 tenía_vmii000 seis_dn0000 años_nc0p000vi_vmis000 en_sp000 un_di0000 libro_nc0s000 sobre_sp000 la_da0000 selva_nc0s000 virgen_nc0s000 que_cs se_p0000000 titulaba_vmii000 "_fe Historias_np00000 vividas_aq0000 "_fe ,_fcuna_di0000 magnífica_aq0000 lámina_nc0s000 ._fpRepresentaba_vmii000 una_di0000 serpiente_nc0s000 boa_np00000 que_pr000000 se_p0000000 tragaba_vmii000 a_sp000 una_di0000 fiera_nc0s000 ._fp
6.3 tTAG
Primero de todo, recomiendo leer el cuadro 5 donde aparecen todas las etiquetas Penn Treebank y su significado. Una vez consultado el cuadro, el resultado proporcionado del texto en inglés es el siguiente:
Once_RB when_WRB ([ I_PRP ])
<: was_VBD>([ six_CD years_NNS ]) old_JJ ([ I_PRP ])
<: saw_VBD>([ a_DT magnificent_JJ picture_NN ]) in_IN ([ a_DT book_NN ]),_,
<: called_VBD>([ True_NNP Stories_NNP ]) from_IN ([ Nature_NNP ]),_, about_IN ([ the_DT primeval_JJ forest_NN
])._.([ It_PRP ])
<: was_VBD>([ a_DT picture_NN ]) of_IN ([ a_DT boa_NN constrictor_NN ]) in_IN ([ the_DT act_NN ]) of_IN
swallowing_VBG ([ an_DT animal_NN ])._.Here_RB
<: is_VBZ>([ a_DT copy_NN ]) of_IN ([ the_DT drawing_NN ])._.
Para el texto en castellano, tenemos el siguiente resultado: ([ Cuando_NNP ]) yo_FW tenía_FW seis_FW años_FW vi_FW en_FW un_FW libro_FW sobre_FW la_FW selva_FW virgen_FW que_FW se_FWtitulaba_FW "_'' ([ Historias_NNP vividas_NNS ])"_" ,_,una_FW magnífica_FW lámina_FW ._.([ Representaba_NNP ]) una_FW serpiente_FW ([ boa_NN ]) que_FW se_FW tragaba_FW a_FW una_FW fiera_FW ._.
| Number | Tag | Description |
|---|---|---|
| 1. | CC | Coordinating conjunction |
| 2. | CD | Cardinal number |
| 3. | DT | Determiner |
| 4. | EX | Existential there |
| 5. | FW | Foreign word |
| 6. | IN | Preposition or subordinating conjunction |
| 7. | JJ | Adjective |
| 8. | JJR | Adjective, comparative |
| 9. | JJS | Adjective, superlative |
| 10. | LS | List item marker |
| 11. | MD | Modal |
| 12. | NN | Noun, singular or mass |
| 13. | NNS | Noun, plural |
| 14. | NNP | Proper noun, singular |
| 15. | NNPS | Proper noun, plural |
| 16. | PDT | Predeterminer |
| 17. | POS | Possessive ending |
| 18. | PRP | Personal pronoun |
| 19. | PRP\$ | Possessive pronoun |
| 20. | RB | Adverb |
| 21. | RBR | Adverb, comparative |
| 22. | RBS | Adverb, superlative |
| 23. | RP | Particle |
| 24. | SYM | Symbol |
| 25. | TO | to |
| 26. | UH | Interjection |
| 27. | VB | Verb, base form |
| 28. | VBD | Verb, past tense |
| 29. | VBG | Verb, gerund or present participle |
| 30. | VBN | Verb, past participle |
| 31. | VBP | Verb, non-3rd person singular present |
| 32. | VBZ | Verb, 3rd person singular present |
| 33. | WDT | Wh-determiner |
| 34. | WP | Wh-pronoun |
| 35. | WP\$ | Possessive wh-pronoun |
| 36. | WRB | Wh-adverb |
5 Tabla de etiquetas
7. Observaciones sobre la comparativa de los resultados.
Para realizar esta comparativa del texto en inglés, lo primero que debemos analizar es las etiquetas utilizadas y, en mi experimento, los tres sistemas han utilizado las mismas etiquetas Penn Treebank, lo que facilita la tarea. Ahora bien, no todos han utilizado el mismo nombre para las etiquetas. Al analizar los resultados y la documentación aportada he observado las siguientes diferencias entre TreeTagger y los sistemas Stanford Log-linear Part-Of-Speech Tagger y tTAG:- En TreeTagger los pronombres personales se etiquetan como PP mientras que en Stanford Log-linear Part-Of-Speech Tagger y tTAG se etiquetan como PRP. Ejemplo:
Word TreeTagger Stanford Log-linear Part-Of-Speech Tagger y tTAG I PP PRP It PP PRP - En TreeTagger los verbos en pasado los interpreta como VVD mientras que en se en Stanford Log-linear Part-Of-Speech Tagger y tTAG se etiquetan como VBD. Ejemplo:
Word TreeTagger Stanford Log-linear Part-Of-Speech Tagger y tTAG saw VVD VBD called VVD VBD - En TreeTagger los nombres propios se interpretan como NP mientras que en se en Stanford Log-linear Part-Of-Speech Tagger y tTAG se etiquetan como NNP. Ejemplo:
Word TreeTagger Stanford Log-linear Part-Of-Speech Tagger y tTAG true NP NNP nature NP NNP stories NP NNP
yo_FW tenía_FW seis_FW
Si analizamos el resultado expuesto podemos analizar como el etiquetador considera yo, tenía y seis como que poseen la misma funcionalidad léxica FW cuando yo es un pronombre, tenía un verbo y seis un sustantivo. Lo que me hace pensar que tTag en su versión web no esta preparada para textos en otros idiomas y la etiqueta FW será como un etiqueta para indicar que una palabra es desconocida para el modelo. Por su parte, la herramienta Stanford Log-linear Part-Of-Speech Tagger muestra las etiquetas propias de un modelo implementado por ellos mucho más completo que Penn Treebank, dotando al usuario de mucha más información. Se puede consultar en la dirección https://nlp.stanford.edu/software/spanish-faq.shtml. Por último, con TreeTagger utilizamos el mismo funcionamiento y etiquetado utilizando el modelo en ingles que en castellano. Comparando ambos resultados, el proporcionado por TreeTagger y Stanford Log-linear Part-Of-Speech Tagger, el segundo etiquetador nos proporciona más información que el primero sobre sus funcionalidades léxicas, por lo tanto, gracias al modelo utilizado, considero que es una mejor opción que el segundo.