Bases de datos distribuidas y Map Reduce.
Contexto actual e histórico
Radar COVID es aquí un caso histórico de 2020, no un servicio vigente ni una arquitectura recomendada para un despliegue sanitario actual. Sus cifras y decisiones deben interpretarse en el contexto de emergencia de aquel momento, con especial atención a privacidad, minimización, retención y evaluación de impacto.
CAP tampoco permite etiquetar una base como AP o CP en todo momento: describe las decisiones posibles cuando existe una partición de red. En condiciones normales también importan latencia, consistencia por operación, quórums, recuperación, residencia del dato y coste. MapReduce sigue siendo un modelo didáctico útil, aunque muchas cargas actuales se resuelven mediante motores SQL distribuidos, procesamiento por lotes o streaming.
- Diseña partición y clave desde las consultas y evita puntos calientes.
- Prueba pérdida de nodos, retraso de réplicas, restauración y reequilibrado.
- No deduzcas la tecnología adecuada multiplicando usuarios por contactos: modela qué datos se almacenan realmente.
- App Radar Covid, análisis de la solución.
- Bases de datos distribuidas.
- Diseñar una solución general para una base de datos NoSQL orientada a documentos.
- Map Reduce.
- Configuración de réplicas.
La página se ha organizado como un caso práctico de arquitectura de datos: primero se analiza una aplicación real de rastreo de contactos, después se revisan conceptos de distribución y replicación, y finalmente se aterriza el modelo MapReduce. El objetivo no es solo definir NoSQL, sino explicar qué decisiones afectan a disponibilidad, consistencia, rendimiento y mantenimiento.
Para ampliar el contexto puedes leer también conceptos básicos y modelos NoSQL, MongoDB frente a Cassandra y diseño de un data warehouse.
App Radar Covid, análisis de la solución
El pasado 10 de septiembre se publicó el código fuente de la aplicación “Radar COVID” para móviles ( referencia ). La aplicación “Radar COVID” se utiliza para el rastreo de contactos y cuarentenas de la enfermedad SARS-CoV-2.El funcionamiento de este tipo de aplicaciones es el siguiente: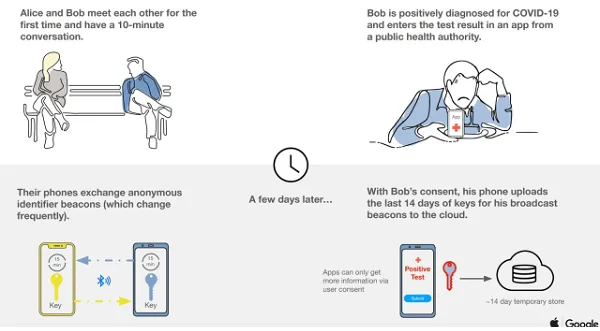
Bases de datos distribuidas.
A partir de la lectura del libro NoSQL Distilled (Descarga) he respuesto las siguientes afirmaciónes:Hash consistente
A pesar del mecanismo de distribución de claves entre nodos de un sistema distribuido mediante la técnica del hash consistente, las claves asociadas a un nodo que falla no se pueden rebalancear entre el resto.FalsoSharding also introduces some problems. If the node used to store f goes down, the data stored on that node becomes unavailable, nor can new data be written with keys that start with f.
Data stores such as Riak allow you to control the aspects of the CAP Theorem (“The CAP Theorem,” p. 53): N (number of nodes to store the key-value replicas), R (number of nodes that have to have the data being fetched before the read is considered successful), and W (the number of nodes the write has to be written to before it is considered successful).
Let’s assume we have a 5-node Riak cluster. Setting N to 3 means that all data is replicated to at least three nodes, setting R to 2 means any two nodes must reply to a GET request for it to be considered successful, and setting W to 2 ensures that the PUT request is written to two nodes before the write is considered successful.
These settings allow us to fine-tune node failures for read or write operations. Based on our need, we can change these values for better read availability or write availability. Generally speaking choose a W value to match your consistency needs; these values can be set as defaults during bucket creation.
Capítulo 8.2.5. Scaling [2] Tal y como vemos en este extracto, realmente lo que acontece en un sistema distribuido de claves es la redundancia de información en diferentes nodos. En este extracto se analiza un ejemplo basado en Riak dónde las claves asociadas a un nodo que falla se pueden obtener mediante consultas a otros nodos que disponen de esa información. Es decir, el sistema aumenta la disponibilidad a través de la replicación de un mismo objeto. De esta forma, si un nodo falla, el objeto puede obtenerse de los otros nodos que contienen la réplica.Modelo de replicación peer-to-peer
El modelo de replicación peer-to-peer tiene como principal inconveniente la consistencia de la información. Verdadero.The biggest complication is, again, consistency. When you can write to two different places, you run the risk that two people will attempt to update the same record at the same time—a write-write conflict. Inconsistencies on read lead to problems but at least they are relatively transient. Inconsistent writes are forever.
Capítulo 4.4. Peer-to-Peer Replication [2] Lo dice claramente el texto citado, la mayor complicación es la consistencia. Cuando se puede escribir en dos lugares diferentes, se corre el riesgo de que dos personas intenten actualizar el mismo registro al mismo tiempo: un conflicto de escritura-escritura.Consistencia Fuerte
Cuando hablamos de consistencia fuerte, en el contexto de replicación, nos referimos a que siempre obtenemos valores consistentes (el mismo valor) cuando se lee de diferentes réplicas, aunque alguna de estas réplicas pueda tener valores inconsistentes.VerdaderoYou do not need to contact all replicants to preserve strong consistency with replication; you just need a large enough quorum.
Capítulo 5.7. Key Points [2] Según los apuntes:- N (factor de replicación): número de réplicas queexisten de unos mismos datos
- W: número de réplicas que deben ser escritas deforma atómica por una operación de escritura
- R: número de réplicas que deben ser recuperadaspara la resolución de una operación de lectura
Partimos de una situación inicial donde todas las réplicas tienen los mismos valores. En primer lugar, se ejecuta la operación de escritura.
El nuevo valor para la réplica es A. Atendiendo a W se deberán escribir de forma síncrona dos réplicas cualesquiera. Las réplicas elegidas han sido X1 y X2. La operación de lectura (que se ejecuta en segundo lugar) lee también dos réplicas. Una de ellas (en concreto X2) contiene el valor correcto que será el que finalmente se devolverá al usuario.
Para concluir destacar que la estrategia garantiza que los usuarios tengan una visión consistente de la base de datos (bajo su punto de vista, todas las réplicas contienen los mismos valores). Sin embargo, realmente, esto no es así tal y como muestra la figura. Este nivel de consistencia se conoce como strong consistency (o consistencia fuerte). En cualquier caso, todas las réplicas acabarán convergiendo a unos mismos valores.
Este último extracto confirma la afirmación. No todos los nodos tienen la información actualizada pero el procedimiento de lectura ha obtenido el dato correcto. Es decir, obtenemos valores consistentes, aunque alguna de estas réplicas puedan tener valores inconsistentes.Modelo map-reduce
En el modelo map-reduce, no todas las funciones de reducción son combinables.Verdadero.Not all reduce functions are combinable. Consider a function that counts the number of unique customers for a particular product. The map function for such an operation would need to emit the product and the customer. The reducer can then combine them and count how many times each customer appears for a particular product, emitting the product and the count (see Figure 7.5). But this reducer’s output is different from its input, so it can’t be used as a combiner. You can still run a combining function here: one that just eliminates duplicate product-customer pairs, but it will be different from the final reducer.
Capítulo 7.2. Partitioning and Combining [2] No todas las funciones de reducción son combinables. En este extracto se ha puesto un ejemplo dónde la salida de un reductor es diferente de su entrada y, por lo tanto, no se puede usar como combinador.Diseñar una solución general para una base de datos NoSQL orientada a documentos.
Un sistema de gestión de críticas de videojuegos mantiene la siguiente información:- Juegos caracterizados por identificador, género, título, fecha de publicación y plataformas.
- Cada juego puede haber recibido Premios caracterizados por la categoría, el nombre del premio y el año de concesión.
- Así mismo cada juego recibe una serie de Críticas caracterizadas por su calificación (puntuado de 0 -pésimo- a 10 -obra maestra-), el medio que publicó la crítica, su autor y la fecha.
- También recibe una Puntuación dada por los jugadores que contiene una puntuación (del 1 a 5) y el número de votos.
- Para cada plataforma se pide la lista de juegos premiados agrupados por año de producción, junto al nombre del juego, el promedio de calificaciones de las críticas, la puntuación obtenida y las listas de premios concedidos.
- Por cada medio de comunicación donde se publican críticas y por cada año, se quiere por cada grupo de calificaciones (0-5, 5-7, 7-9, 9-10) el número de juegos con esa calificación.
- Por cada año y género la lista de los 3 mejores juegos ordenados (de mayor a menor) por las puntuaciones recibidas.
- Explicación del agregado.
- Diseño de cada consulta de acuerdo con lo especificado al principio del enunciado. Los agregados se deben escribir en formato JSON.
Explicación del agregado.
Las bases de datos NoSQL orientas a documentos se caracterizan por garantizar la atomicidad de las operaciones a nivel de documento. De esta forma, las operaciones serán atómicas mientras se inserte o modifique la información del documento. Para las consultas propuestas he creado documentos JSON que incluyen toda la información necesaria y se organice el documento de forma que esté los datos tal y como los pide la consulta para optimizar el rendimiento.Para cada plataforma se pide la lista de juegos premiados agrupados por año de producción, junto al nombre del juego, el promedio de calificaciones de las críticas, la puntuación obtenida y las lista de premios concedidos.
Para registrar la información relativa a los juegos premiados para cada plataforma, tendremos una lista de años por cada plataforma. Dentro de cada año, tendremos los diferentes juegos producidos con su puntuación, el promedio de calificaciones y un listado de premios. Por cada medio de comunicación donde se publican críticas y por cada año, se quiere por cada grupos de calificaciones (0-5, 5-7, 7-9, 9-10) el número de juegos con esa calificación.
Para registrar las críticas publicadas por cada medido de comunicación crearemos un agregado dónde por cada medido de publicación almacenaremos su nombre y un listado de años. Para cada a año dispondremos de un listado de calificaciones. Este listado estará compuesto por los rangos 0-5, 5-7, 7-9, 9-10 dónde en cada clave se almacenará el total de juegos calificados con esa puntuación. Por cada año y género la lista de los 3 mejores juegos ordenados (de mayor a menor) por las puntuaciones recibidas.
Para registrar los 3 mejores juegos por año y género, primero creamos un agregado por cada género. Este agregado contendrá su nombre y un listado con los diferentes años. Cada año tendrá un listado con los 3 juegos mejor puntuados. Este listado estará compuesto por 3 claves, la 1 para el juego más valorado, la 2 para el segundo y la 3 para el tercer juego mejor clasificado. Map Reduce
Dada una estructura con los siguientes datos. Sobre estos datos aplicamos las siguientes funciones: map y reduce.medskip
Se pide: - Describir qué hace la función map y qué valores emite.
- Describir qué hace la función reduce y qué valor obtiene.
Descripción de la función map y qué valores emite.
El objetivo de esta función es agrupar los diferentes elementos de la variable cars entorno a una clave. Esta clave tiene dos posibilidades; underspeed para aquellos coches con un valor speed de 70 o inferior y overspeed cuando sea superior a 70.Es decir, esta función se encarga del mapeo de los datos y se aplica a cada elemento individualmente. Una vez clasificado un elemento, es emitido una señal con el valor de la clave y su velocidad. Como resultado se emitirán las siguientes señales: Descripción de la función reduce y qué valor obtiene.
La función Reduce se aplica en paralelo para cada grupo creado por la función Map(). La función Reduce se llama una vez para cada clave única de la salida de la función Map. Junto con esta clave, se pasa una lista de todos los valores asociados con la clave para que pueda realizar el cálculo de la media de las velocidades consideradas overspeed. Este cálculo únicamente se realizará para aquellos vehículos que se etiqueten como overspeed, para el resto se dejará a 0. Los resultados de esta función son los siguientes:| Entrada | Resultado |
|---|---|
| overspeed, [72,89,94] | 85 |
| underspeed, [65,53] | 0 |
Ejemplos de bases de datos distribuidas
Suponed que debemos configurar el sistema de replicación de una base de datos para que cumpla con consistencia fuerte y se nos plantean distintas alternativas:- Uso de un sistema con 5 réplicas y con una gestión de réplicas con consistencia síncrona.
- Uso de quórums con los siguientes parámetros: N=5, R=2, W =1
- Uso de quórums con los siguientes parámetros: N=5, R=1, W =5
- Uso de quórums con los siguientes parámetros: N=5, R=3, W =3
- ¿Cuál de estas alternativas escogerías (escoge sólo una) teniendo en cuentaque hay un número de lecturas y escrituras parecidas? Indica para cada alternativa porqué la escogerías o rechazarías.
- Uso de un sistema con 5 réplicas y con una gestión de réplicas con consistencia síncrona.No escogidaEn esta estrategia no se pueden generar inconsistencias, dado que los cambios son inmediatamente propagados a todas las réplicas antes de dar por confirmada la operación. Si la propagación no es posible (por ejemplo, debido a que algún nodo que contiene una réplica secundaria no está accesible o disponible), la operación de escritura es rechazada por el sistema y la situación se reporta a la aplicación. Las operaciones de lectura se pueden servir a partir de cualquier réplica y siempre se obtendrá el valor más recientemente confirmado.El principal problema de esta política es que el nodo que contiene la réplica primaria constituye un cuello de botella en el rendimiento, y éste se puede ver aún más degradado porque la consistencia de las réplicas se realiza de manera síncrona.Además, si el nodo que contiene la réplica primaria falla, la disponibilidad del sistema se verá limitada, dado que únicamente se podrán servir operaciones de lectura.Conclusión, hay soluciones que nos ofrecerán un mayor rendimiento sin perder la consistencia fuerte de los datos.
- Uso de quórums con los siguientes parámetros: N=5, R=2, W =1No escogidaPara cumplir con la consistencia fuerte de los datos es necesario escribir de forma atómica al menos la mitad más una de las réplicas que de unos mismos datos existen. Esto evita que se puedan perder cambios y asegura que al menos existe una réplica que contiene el valor correcto (es decir, el más recientementeconfirmado). En este caso, W es 1, es decir, no se cumple 2.5 1 y por lo tanto, no hay consistencia fuerte.
- Uso de quórums con los siguientes parámetros: N=5, R=1, W =5No escogidaEn este caso cumplimos la consistencia de los datos: 2.5 5 y siempre se recuperará, al menos, una réplica que contendrá el valor correcto. Esto es así porque entre los conjuntos de réplicas accedidos para escritura y lectura siempre existe intersección.Para calcular este valor se ha realizado el siguiente cálculo: En este caso, 5 + 1 > 5. Ahora bien, es un caso idéntico a la primera opción. El nodo que contiene la réplica primaria constituye un cuello de botella en el rendimiento, y éste se puede ver aún más degradado porque la consistencia de las réplicas se realiza de manera síncrona.Además, si el nodo que contiene la réplica primaria falla, la disponibilidad del sistema se verá limitada, dado que únicamente se podrán servir operaciones de lectura.A todo esto, los procesos de escritura son muy lentos lo que provoca una merma de rendimiento.
- Uso de quórums con los siguientes parámetros: N=5, R=3, W =3Solución EscogidaEsta solución cumple los dos teoremas: Este sistema garantiza la consistencia fuerte. Esta configuración evita que se puedan perder cambios y asegura que al menos existe una réplica que contiene el valor correcto y siempre se recuperará, al menos, una réplica que contendrá el valor correcto.Además tener un nodo caído o problemas de escritura en 2 nodos no supondrá una merma de las capacidades del sistema, ya que no existirá ningún cuello de botella.
- Supón que queremos configurar las réplicas de la colección de clientes de nuestra base de datos de manera que satisfagan una consistencia final en el tiempo. Sabemos que la colección de clientes recibe muchas solicitudes de lectura y pocas de escritura. ¿Cual de estas dos alternativas de quórum elegirías? Justifica tu respuesta.
- N=3, R=1, W=2Escogida
- N=3, R=2, W=1No escogida