Estado del arte sobre predicción de Bitcoin
Esta sección revisa trabajos previos sobre predicción del precio de Bitcoin, análisis de sentimiento, polaridad reputacional y modelos de PLN aplicados a señales sociales. Sirve de contexto para las secciones posteriores del TFM, donde sentimiento clásico e impacto reputacional se tratan como variables relacionadas pero diferentes.
2.Estado del Arte
Para comprobar el grado de correlación entre el precio del Bitcoin con la polaridad reputacional y del sentimiento es necesario conocer ambos términos y que algoritmos pueden ayudarnos a obtener este fin. La sección [2.1] analizarán las diferencias entre las técnicas del análisis de sentimientos y la polaridad reputacional a partir de los estudios previos publicados sobre el tema. En la sección [2.2] se analizan diferentes estudios realizados sobre la predicción del valor el valor Bitcoin a partir de redes sociales.2.1. Análisis de sentimientos vs polaridad reputacional
Como hemos comentado en la sección [1.2] , la reputación online es un reflejo del prestigio de una persona o una marca en Internet. Para poder cuantificar la reputación de una entidad, un algoritmo predictivo debe ser capaz de analizar un documento con el objetivo de encontrar la información más relevante y clasificarla acorde a sus implicaciones positivas, neutrales o negativas, es decir, debe utilizar las técnicas para el Procesamiento del Lenguaje Natural con el objetivo de poder interpretar sus implicaciones reputacionales. En este sentido, en el estudio del arte aplicado en esta sección se ha podido observar como el análisis de sentimiento es la herramienta de Procesamiento del Lenguaje Natural más utilizada para la monitorización de la reputación online. Obras como [Sentiment Analysis or Opinion Mining: A Review] [30] son un ejemplo de esta afirmación, a pesar de como se ha demostró en [European Conference on Information Retrieval] [21] que los sentimientos de un texto y sus implicaciones reputacionales para esa entidad son cosas diferentes. Realmente, la mayoría de los textos con implicaciones reputacionales son polar facts, es decir, información factual sin sentimientos explícitos. Por supuesto, medir la polaridad reputacional de un texto es más complicado cuando el documento no expresa implícitamente una reputación positiva o negativa sobre el tema analizado; pero invertir recursos en este caso puede proporcionar a las entidades aplicaciones positivas, por ejemplo, para obtener datos de opinión no estructurados sobre un servicio o producto. A pesar de que por definición la polaridad reputacional es substancialmente diferente al sentimiento de análisis, las dos tienen algunas similitudes. Es más, los trabajos sobre la polaridad reputacional han evolucionado a partir de estudios previos sobre el análisis de sentimientos, es decir, el proceso de resolver (estadísticamente) si un texto contiene sentimientos positivos, negativos o neutrales con respecto a la entidad de interés. Como ya hemos comentado, los trabajos sobre la recuperación de opinión y análisis de sentimientos se puede dividir en dos categorías: enfoques basados en léxico y en clasificación supervisada. Los enfoques basados en léxico estiman el sentimiento de un documento utilizando una lista de palabras de opinión conocida como léxicos de opinión, como por ejemplo el articulo [Proceedings of the 40th annual meeting on association for computational linguistics] [17] donde se identifica el sentimiento de un documento a través de un diccionario de palabras catalogados acorde a su sentimiento. El enfoque basado en léxico no está supervisado ya que no requiere ningún dato de entrenamiento. Enfoques más sofisticados incorporan indicadores de sentimiento adicionales como la proximidad entre términos de consulta y opinión [13] o variaciones estilísticas basadas en temas [12] . Los enfoques basados en la clasificación usan conjuntos de rasgos para construir un clasificador que pueda predecir el sentimiento de polaridad de un documento [10] . Los rasgos van desde simples n-gramas hasta características semánticas y desde características sintácticas hasta características específicas del medio [9] . Además, los enfoques basados en la clasificación pueden también dividirse en enfoques semi-supervisados y supervisados. La mayor diferencia entre las dos categorías es que los enfoques semi-supervisados combinan datos etiquetados y no etiquetados. En el artículo [Opinion Mining and Sentiment Analysis. Foundations and Trends in Information Retrieval] [8] se puede encontrar una revisión exhaustiva sobre la recuperación de opinión y el análisis de sentimientos. Mientras que en la obra [Like it or not: A survey of twitter sentiment analysis methods] [7] , encontraron una búsqueda exhaustiva centrada en el análisis de sentimientos de Twitter. A partir de los trabajos sobre los métodos de análisis de sentimientos se establecieron los primeros enfoques para el análisis de la polaridad reputacional llegando a conseguir los mejores resultados con modelos entrenados a partir de características textuales y de sentimiento. El mejor resultado fue logrado en el artículo [CEUR WORKSHOP PROCEEDINGS] [6] quienes entrenaron a un clasificador de máxima entropía utilizando el léxico de sentimientos, diagramas , número de palabras de negación y repeticiones de caracteres. [CLEF 2013 Conference and Labs of the Evaluation Forum] [5] , abordó el problema de la polaridad de reputación con un enfoque basado en la recuperación de información y encontró la clase más relevante utilizando el contenido del tweet como una consulta. [Estimating reputation polarity on microblog posts] [4] , asumió que entender cómo se percibe un tweet es un indicador importante para la estimación de polaridad reputacional de un tweet. Con tal fin, propusieron un enfoque supervisado que también consideró características de recepción como las respuestas y retweets de tweets. Los resultados mostraron que estas características fueron efectivas y que su mejor resultado se obtuvo en datos dependientes de la entidad. Nuestra contribución será investigar la técnica contextual de word embeddings en su implementación en el sistema BERT en la sección [2.1.1.] en la estimación de la polaridad reputacional de los tweets y a la predicción de valores bursátiles, comparándola con el análisis del sentimiento.2.1.1 Procesamiento del Lenguaje Natural
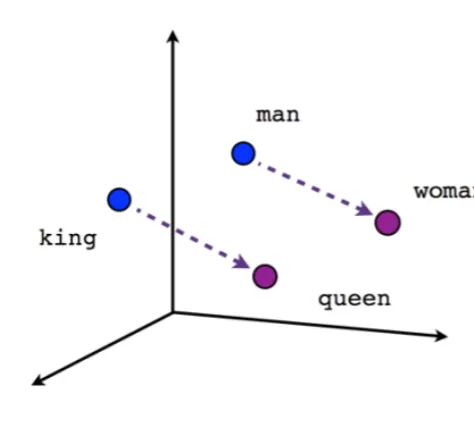
Como hemos podido comprobar en la sección [2.1] , la polaridad reputacional puede utilizar los mismos algoritmos que utilizan los analistas de datos para medir la polaridad del sentimiento. Basándonos en esa premisa, esta sección del proyecto tendrá como objetivo investigar el campo del Procesamiento del Lenguaje Natural (PLN). Como hemos analizado anteriormente, el procesamiento de textos por medio de la inteligencia artificial supone un reto al momento de presentar un texto determinado en un algoritmo y que este lo entienda en su totalidad, preservando las características del lenguaje. El procesamiento del lenguaje natural moderno (a partir de 2013) utiliza con frecuencia la técnica de los embeddings, representaciones de palabras en un vector n-dimensional, partiendo de la premisa de que su cercanía espacial conlleva alguna clase de relación entre los mismos. En las figuras [1] [2] [3] se pueden analizar 3 ejemplos gráficos de este algoritmo.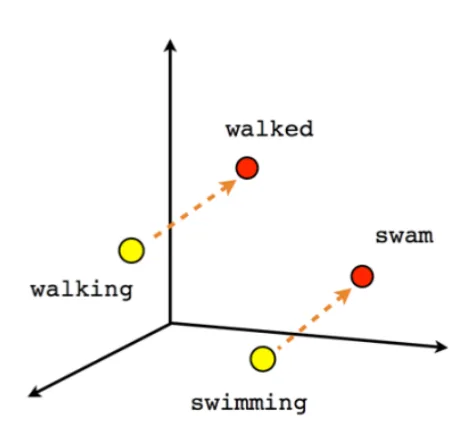
Proximidad de localización
Como se puede comprobar, el primer paso de este algoritmo es asignar a cada palabra un vector de números a partir de su contenido semántico (cabe recordar que las redes neuronales son más eficientes con números). Si se analiza la imagen [1] , se observa un ejemplo semántico de cómo se representarían cuatro palabras diferentes pero relacionas en un espacio vectorial. Si se realiza una operación matemática como: Rey menos hombre más mujer se obtendrá como resultado un vector muy cercano al que se ha representado Reina. Esta evolución permite utilizar sistemas de redes neuronales para comprender la semántica de las palabras, aunque sin llegar a comprender las relaciones entre las mismas. Para resolver esta carencia, las técnicas del NLP han mejorado lo suficiente hasta llegar a generar lo que hoy conocemos como `modelos de lenguaje'. Los modelos de lenguaje son patrones de Machine Learning destinados a predecir cuál ha de ser la siguiente palabra de un texto en función de todas las palabras anteriores. El gran potencial de esta técnica es que, una vez que la IA comprende la estructura de un lenguaje, es relativamente fácil descargar estos modelos preentrenados y adaptarlos mediante `fine-tuning' a otras tareas diferentes a la creación de textos, como puede ser la clasificación de textos. Dentro de todos los sistemas publicados hasta el momento y después de realizar una búsqueda entre diferentes soluciones, en esta investigación nos hemos decantado por BERT, uno de los modelos más avanzados para la representación de palabras y textos. BERT es un sistema que proporciona contextual word embeddings, es decir, cada palabra recibe una representación dependiente del contexto en el que aparece. Los contextual word embeddings son sistemas preentrenados que proporcionan una riqueza semántica sin precedentes, y que están cambiando el PLN desde el año 2018. Aunque hay varios sistemas que compiten con BERT en la actualidad, el hecho de que BERT sea de código abierto y bien documentado hace que sea la opción más popular y la que hemos adoptado en este trabajo.Bert
Como se ha podido comprobar a través del contenido de esta sección, para poder clasificar la polaridad reputacional de un texto será necesario tanto el análisis del documento mediante espacio de vectores como el análisis del contexto en el que ocurren las palabras. Las consecuencias de esta nueva interpretación las podemos ver reflejadas en la palabra rey del ejemplo anterior, ya que poseerá un significado diferente dependiendo del contexto en el que se use la palabra. Esta sutileza es necesaria, ya que capturar el sentido gramático de las palabras puede aportar información relevante sobre su polaridad. Por ejemplo, no es lo mismo utilizar una palabra como objeto o como sujeto en una oración, con un sentido o con otr En este sentido, las técnicas de procesamiento de lenguaje natural (PLN) basadas en algoritmos de inteligencia artificial (IA) nos ofrecerá una mejor solución que los algoritmos analizados hasta ahora. Para ello se puede utilizar la experiencia previa de este campo en la traducción de idiomas, análisis de sentimientos o búsqueda semántica que ofrecerá una ayuda a la hora de escoger el mejor camino para nuestra tarea. Otro beneficio de obtener la experiencia previa en otras tareas es la capacidad de optimizar más eficientemente el modelo creado. Estos algoritmos necesitan alimentarse de diversos conjuntos de datos lo suficientemente grandes como para entrenar los modelos que utilizan. Los algoritmos de aprendizaje profundo imitan el comportamiento de las neuronas en el cerebro humano, es decir, a medida que aumenta el conjunto de entrenamiento mejoran sus resultados y, por lo tanto, cualquier conjunto ya etiquetado nos puede ayudar a obtener mejores resultados en el proyecto. Ahora bien, debido a que el PLN es un campo con muchas tareas distintas, la mayoría de los conjuntos de datos específicos de tareas contienen solo unos pocos miles o unos cientos de miles de ejemplos de documentos etiquetados por el hombre. Para ayudar a cerrar esta brecha en los datos, los investigadores han desarrollado una variedad de técnicas para entrenar modelos de representación de lenguaje de propósito general utilizando la enorme cantidad de texto no anotado en la web (conocido como pre-entrenamiento). El modelo pre-entrenado puede luego ajustarse a tareas de PLN de datos pequeños como la respuesta a preguntas y el análisis de sentimientos, lo que resulta en mejoras sustanciales de precisión en comparación con la capacitación en estos conjuntos de datos desde cero. Y en este contexto, el 2 de noviembre del 2018 Google presentaba Open Sourcing BERT (Bidirectional Encoder Representations from Transformers), el primer modelo contextual profundamente bidireccional, representación de lenguaje sin supervisión, pre-entrenado usando solo un corpus de texto plano. BERT se basa en el trabajo reciente en representaciones contextuales previas al entrenamiento, que incluye el Aprendizaje de Secuencia Semi-supervisado, el Pre-Entrenamiento Generativo, ELMo y ULMFit. Sin embargo, a diferencia de estos modelos anteriores, BERT es la primera representación de lenguaje no supervisada, profundamente bidireccional, pre-entrenada usando solo un corpus de texto simple. Según lo explicado por Jacob Devlin y Ming-Wei Chang, investigadores de Google AI, BERT es único porque es bidireccional y permite el acceso al contexto desde direcciones pasadas y futuras y desatendido, lo que significa que los datos se pueden capturar sin clasificar ni marcar. Esto contrasta con los modelos tradicionales de PLN que producen una incrustación de palabras sin contexto (una representación matemática de una palabra) para cada palabra en su vocabulario. Las representaciones pre-entrenadas pueden ser libres de contexto o contextuales, y las representaciones contextuales pueden ser unidireccionales o bidireccionales. Los modelos sin contexto comentados anteriormente generan una representación de incrustación de una sola palabra para cada palabra en el vocabulario. Por ejemplo, la palabra "banco'' tendría la misma representación libre de contexto en "cuenta bancaria'' y "banco del río''. En su lugar, los modelos contextuales generan una representación de cada palabra que se basa en las otras palabras de la oración. Por ejemplo, en la oración "Accedí a la cuenta bancaria'', un modelo contextual unidireccional representaría "banco'' basado en "Accedí a la'' pero no a "cuenta''. Sin embargo, BERT representa "banco'' utilizando su contexto anterior y el siguiente. "Accedí a la [...] cuenta'', comenzando desde el fondo de una red neuronal profunda, haciéndola profundamente bidireccional. A continuación, se muestra una visualización de la arquitectura de la red neuronal de BERT en comparación con los métodos de entrenamiento previo contextual más avanzados. Las flechas indican el flujo de información de una capa a la siguiente. Los cuadros verdes en la parte superior indican la representación contextualizada final de cada palabra de entrada: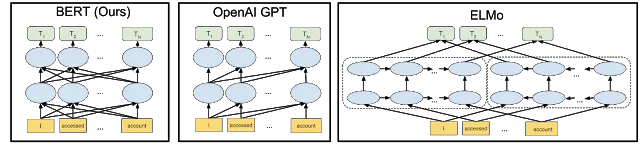
2.2. Predicción del valor Bitcoin a partir de redes sociales
En los mercados de divisas tradicionales es común ver a los inversores utilizar alguno de los siguientes enfoques (en conjunto o por separado) para predecir las tendencias del mercado:- Análisis fundamental: la técnica que utiliza los factores subyacentes de un valor para estimar su valor. En relación con las monedas emitidas por el Estado, esta técnica se centra en indicadores como las previsiones de crecimiento de una nación, los niveles de importación y exportación, el turismo, las medidas políticas, los niveles de deuda, el PIB y las relaciones internacionales. Éstos se utilizan como parámetros para un modelo de valoración. Si se considera que la moneda está por debajo del precio, entonces tiene sentido comprar esa moneda, de lo contrario para vender. El artículo Madan et al. [28] es un ejemplo de este enfoque. En él se observó que la investigación existente no consideraba la relación entre otros factores en el espacio de características y la estimación de precios de Bitcoin cuando se aplicaba a un agente comercial. Al analizar 16 características independientes, crearon un algoritmo de aprendizaje automático para predecir el precio de Bitcoin. Estas 16 características están relacionadas con el precio de Bitcoin y se registraron diariamente durante los últimos 5 años. Su estudio también consideró el uso de precios de Bitcoin sólo como un medio de predecir la dirección de los futuros cambios de precios.
- Análisis técnico: es un método alternativo de asignación de valor a una acción que analiza la actividad del mercado analizando datos tales como precios históricos y volumen diario negociado. Este enfoque no intenta medir el valor intrínseco de una seguridad, sino que utiliza modelos matemáticos y análisis estadístico para identificar patrones con el fin de predecir la actividad futura. Un ejemplo de este análisis ese el articulo [Bitcoin Trading Agents] [22] donde se propone predecir el precio del Bitcoin a través de una regresión bayesiana. En el documento se dan n puntos de datos etiquetados ( , ) para 1 . Estos datos de entrenamiento (precios históricos de Bitcoin) se utilizan para predecir la etiqueta desconocida (futuro precio de Bitcoin) dada una x determinada. Es decir, el modelo utilizado se centra en la comprensión de la información que se encuentra en los datos históricos relacionados co
- Blockcain.info donde se ha obtenido toda la información relacionada con estadísticas monetarias, actividad de la red, detalles sobre los bloques, tasas de creación de nuevas monedas y transacciones. Por supuesto, está incluida el valor de intercambio USD a bitcoin y viceversa junto con su volumen.
- Gooogle Trends. Esta plataforma es una herramienta de Google Labs que muestra los términos de búsqueda más populares del pasado reciente. Utilizando la palabra Bitcoin como consulta, se han obtenidos los principales temas relacionados con la criptomoneda.
- Datos macroeconómicos. Los datos macroeconómicos de S&P500, Chicago Board Options Exchange y Volatility Index.